El código fuente para este artículo se puede encontrar aquí.
¡Bienvenido a otro experimento en la nube! La idea detrás de estos tutoriales prácticos es proporcionar experiencia práctica construyendo soluciones cloud-native de diferentes tamaños usando servicios de AWS y CDK. Nos enfocaremos en desarrollar experiencia en Infrastructure as Code, servicios de AWS y arquitectura en la nube mientras entendemos tanto el “cómo” como el “por qué” detrás de nuestras decisiones.
Muerte de una Base de Datos
Me gustan las funciones Lambda, y también me gustan las soluciones de auto-scaling. Es extremadamente conveniente tener un sistema que se escale elásticamente para satisfacer demandas de rendimiento automáticamente, todo con configuración mínima.
Hay algunos desafíos inherentes a este enfoque. Uno de los más comunes ocurre cuando una parte de tu sistema es incapaz de escalar de la misma manera, haciendo que todo el sistema se retrase (en el mejor caso) o simplemente colapse bajo el peso del número masivo de solicitudes que recibe de las partes escaladas de tu sistema.
Postgres es una pieza de software increíble, pero no fue diseñado para manejar automáticamente el número masivo de conexiones entrantes que pueden surgir de sistemas que generan decenas o cientos de entornos de ejecución concurrentes, como las funciones Lambda.
Una buena solución para este problema es usar un proxy RDS para proteger tu base de datos principal de ser sobrecargada por demasiadas conexiones. Tu proxy manejará el pooling de conexiones necesario para gestionar grandes números de lambdas o contenedores concurrentes, salvando a tu pobre base de datos de ser aplastada por muchas más conexiones de las que puede manejar.
Diseñando una Solución
La configuración del problema es una versión simplificada de una arquitectura que eventualmente puedes encontrar en la vida real: Un API Gateway está respaldado por unas pocas funciones Lambda, y estas lambdas obtienen sus datos consultando una instancia RDS. Hay un riesgo inherente con este enfoque porque tus lambdas pueden terminar generando múltiples entornos de ejecución concurrentes para servir las demandas de múltiples usuarios consultando tu API, y juntos abrirán más conexiones de las que tu base de datos puede manejar.
Crearemos un gateway simple con una sola URL y una sola función Lambda. A veces este nivel de complejidad es justo el correcto para entender cómo construir una solución y aprender una habilidad que puede ayudarte a abordar desafíos más grandes y complejos en el trabajo. La arquitectura general de nuestro sistema es la siguiente:
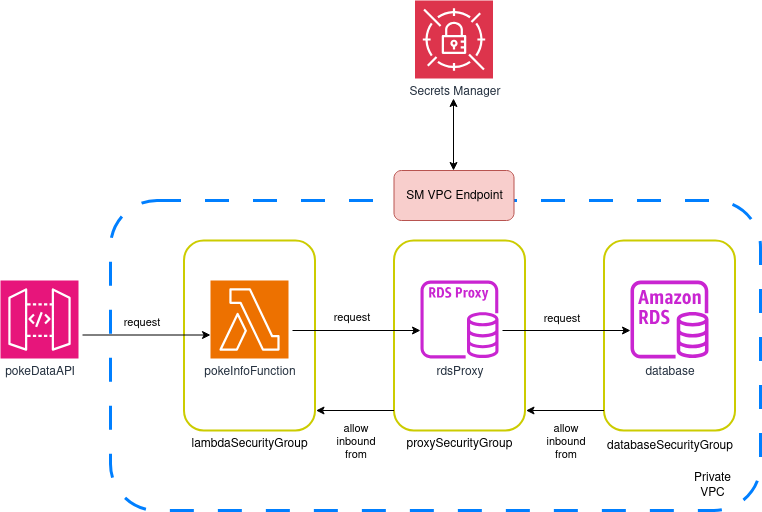
Estudiemos el diagrama por algunos minutos antes de proceder para asegurar que entendemos lo que estamos tratando de lograr.
Detalles del Diseño
El diagrama es sencillo y fácil de entender, pero hay algunos detalles que vale la pena notar:
- Crearemos nuestra propia VPC en lugar de desplegar nuestra solución en la VPC regional por defecto. Normalmente es una buena idea tener redes dedicadas para diferentes partes de tu sistema, y de esta manera podemos asegurar que el acceso a nuestros componentes individuales pueda controlarse fácilmente.
- Nos aseguraremos de que esta VPC tenga subredes en al menos dos zonas de disponibilidad diferentes, y trataremos de mantenerlas pequeñas. Cada subred será privada, y no adjuntaremos ningún mecanismo para acceder a internet (ni un Internet Gateway ni un NAT Gateway).
- Crearemos tres grupos de seguridad: uno para lambdas, uno para el proxy, y uno para la instancia de base de datos. Permitiremos acceso entrante al grupo de seguridad de la base de datos solo desde entidades usando el grupo de seguridad del proxy, y solo permitiremos acceso entrante al grupo de seguridad del proxy desde instancias usando el grupo de seguridad lambda. Esto significa que las lambdas (o cualquier otra instancia) no podrán hablar con la base de datos directamente—el acceso será mediado exclusivamente por el proxy, y solo cuando use el grupo de seguridad lambda.
- Todas las credenciales serán gestionadas por Secrets Manager: El nombre de usuario y contraseña de RDS serán auto-generados y encriptados, y tanto el proxy como las lambdas solicitarán acceso a este secreto para conectarse. Restringiremos y controlaremos el acceso a este secreto usando políticas IAM (bloquear todo a menos que se otorgue permiso explícito).
- No podemos acceder a Secrets Manager desde dentro de una VPC privada sin acceso a internet, así que crearemos y adjuntaremos un endpoint que habilite acceso al servicio desde dentro de cualquiera de nuestras subredes.
- El diseño mostrado arriba usa una sola función Lambda. Haremos algo muy, muy, muy feo: La lambda estará a cargo de proporcionar datos a la única URL en el API Gateway (
<base_url>/poke_data) Y al mismo tiempo estará a cargo de agregar datos de prueba a la base de datos. Esto es algo terrible que nunca deberías hacer en un entorno profesional, pero el objetivo de este laboratorio es proporcionarte un sistema que puedas fácilmente desplegar y ejecutar, así que haremos la vista gorda esta vez.
Ahora que entendemos todas las decisiones de diseño relevantes, ¡podemos empezar a construir nuestro stack!
Construyendo la Solución
Creación del Proyecto
Primero, necesitamos la configuración regular del proyecto a la que nos hemos acostumbrado.
Crea una carpeta vacía (nombré la mía APIGatewayWithProxiedRDS) y ejecuta cdk init app --language typescript dentro de ella.
Este siguiente cambio es opcional, pero lo primero que hago después de crear un nuevo proyecto CDK es dirigirme a la carpeta bin y renombrar el archivo app a main.ts. Luego abro el archivo cdk.json y edito la configuración app:
{
"app": "npx ts-node --prefer-ts-exts bin/main.ts",
"watch": {
...
}
}
Ahora tu proyecto reconocerá main.ts como el archivo de aplicación principal. No tienes que hacer esto—solo me gusta tener un archivo llamado main sirviendo como archivo principal de la app.
Importaciones del Stack
Al mirar el diagrama, sabemos que necesitaremos las siguientes importaciones en la parte superior del stack:
import * as cdk from "aws-cdk-lib";
import { Construct } from "constructs";
import { aws_rds as rds } from "aws-cdk-lib";
import { aws_ec2 as ec2 } from "aws-cdk-lib";
import { aws_lambda as lambda } from "aws-cdk-lib";
import { aws_secretsmanager as secrets } from "aws-cdk-lib";
import { aws_apigatewayv2 as gateway } from "aws-cdk-lib";
import { aws_apigatewayv2_integrations as api_integrations } from "aws-cdk-lib";
Creando la Red y los Grupos de Seguridad
const vpc = new ec2.Vpc(this, "VPC", {
ipAddresses: ec2.IpAddresses.cidr("10.0.0.0/27"),
createInternetGateway: false,
natGateways: 0,
maxAzs: 2,
subnetConfiguration: [
{
cidrMask: 28,
name: "rds-subnet",
subnetType: ec2.SubnetType.PRIVATE_ISOLATED,
},
],
});
vpc.addInterfaceEndpoint("secretsManagerEndpoint", {
service: ec2.InterfaceVpcEndpointAwsService.SECRETS_MANAGER,
});
Esta sección de código crea una VPC sin un NAT Gateway y sin un Internet Gateway. Estaremos ejecutando en máximo dos zonas de disponibilidad, y también queremos subredes con el tamaño más pequeño posible permitido para una subred VPC (un /28 CIDR). Esto significa que el CIDR para la VPC necesita ser al menos el doble de grande, así que definimos un bloque CIDR /27 para toda la red. Si necesitas repasar tu conocimiento de redes sobre CIDRs, puedes echar un vistazo a estos docs.
Cada subred tendrá un total de 16 IPs, pero solo 11 de esas serán utilizables. Esto sucede porque AWS reserva las primeras cuatro y la última (cinco en total) IPs de cada subred.
La VPC se verá más o menos así:
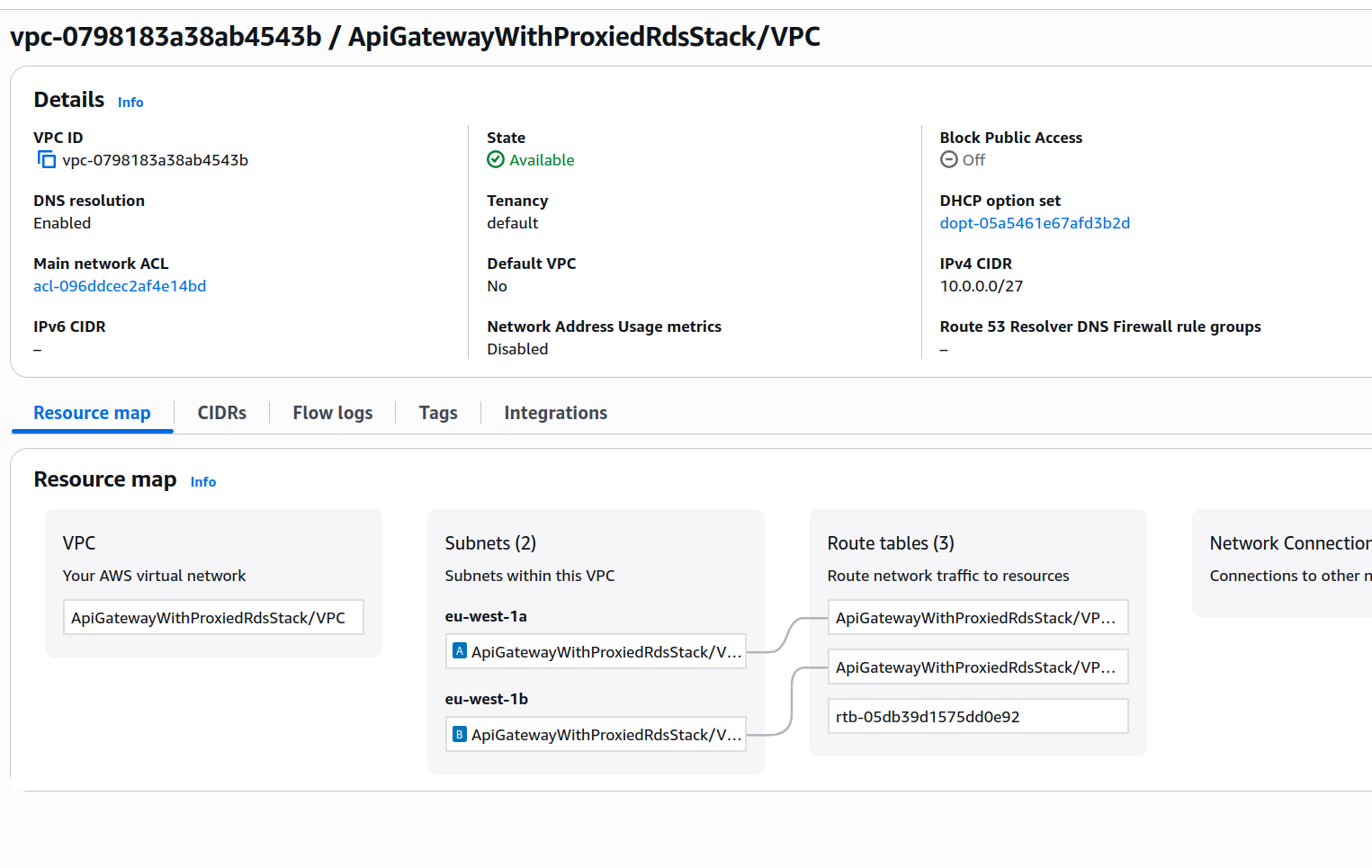
El último paso en el bloque de código anterior adjunta un endpoint de interfaz para habilitar acceso a Secrets Manager desde dentro de nuestra VPC privada.
Los grupos de seguridad se definen como sigue:
const databaseSecurityGroup = new ec2.SecurityGroup(
this,
"databaseSecurityGroup",
{
vpc: vpc,
}
);
const proxySecurityGroup = new ec2.SecurityGroup(
this,
"proxySecurityGroup",
{
vpc: vpc,
}
);
const lambdaSecurityGroup = new ec2.SecurityGroup(
this,
"lambdaSecurityGroup",
{
vpc: vpc,
}
);
databaseSecurityGroup.addIngressRule(proxySecurityGroup, ec2.Port.tcp(5432));
proxySecurityGroup.addIngressRule(lambdaSecurityGroup, ec2.Port.tcp(5432));
Como se discutió en la sección de diseño, definimos tres grupos de seguridad: uno para la base de datos (databaseSecurityGroup), uno para el proxy (proxySecurityGroup), y uno para las lambdas (lambdaSecurityGroup).
Cuando se crea un grupo de seguridad, el comportamiento por defecto es bloquear todo el tráfico entrante, así que en las últimas dos líneas agregamos una declaración para asegurar que el grupo de seguridad del proxy pueda acceder al grupo de seguridad de la base de datos, y que el grupo de seguridad lambda pueda acceder al grupo de seguridad del proxy. Ambas reglas son para tráfico TCP en el puerto 5432 (el puerto de conexión por defecto de Postgres).
Esas Subredes Parecen Bastante Pequeñas, ¿No?
Sí, son bastante pequeñas—¡solo 11 IPs disponibles por subred!
Esto solía ser un problema, pero en 2019 AWS anunció un conjunto importante de cambios:
- Porque las interfaces de red son compartidas a través de entornos de ejecución, típicamente solo un puñado de interfaces de red se requieren por función. Cada combinación única de grupo de seguridad: subred a través de funciones en tu cuenta requiere una interfaz de red distinta. Si una combinación es compartida a través de múltiples funciones en tu cuenta, reutilizamos la misma interfaz de red a través de funciones.
- El escalado de tu función ya no está directamente vinculado al número de interfaces de red y los ENIs Hyperplane pueden escalar para soportar grandes números de ejecuciones de función concurrentes
Así que, en resumen, solo necesitamos 1 IP por combinación lambda+grupo de seguridad. El sistema mismo se asegurará de que eso sea suficiente sin importar cuántos entornos de ejecución concurrentes se creen. Así que sí, incluso nuestras pequeñas subredes serán adecuadas para este escenario.
Creando el Secreto
Necesitamos un secreto para el nombre de usuario y contraseña de nuestra base de datos. Esto es muy fácil de lograr con CDK:
const dbAuthSecret = new secrets.Secret(this, "dbAuthSecret", {
description: `Used as secret for database authentication on ${this.stackName}`,
secretName: `${this.stackName}-db-auth`,
generateSecretString: {
secretStringTemplate: JSON.stringify({
username: "postgres",
}),
generateStringKey: "password",
excludePunctuation: true,
},
});
¡Hemos terminado! Ahora solo podemos referenciar este secreto cuando creemos nuestra instancia de base de datos y nuestro proxy, y ellos manejarán la configuración por sí mismos.
Creando la Instancia RDS y Adjuntando el Proxy
const database = new rds.DatabaseInstance(this, "Database", {
engine: rds.DatabaseInstanceEngine.postgres({
version: rds.PostgresEngineVersion.VER_17,
}),
instanceType: ec2.InstanceType.of(
ec2.InstanceClass.T3,
ec2.InstanceSize.MICRO
),
vpc,
vpcSubnets: {
subnetType: ec2.SubnetType.PRIVATE_ISOLATED,
},
securityGroups: [databaseSecurityGroup],
multiAz: false,
allocatedStorage: 20,
maxAllocatedStorage: 20,
backupRetention: cdk.Duration.days(0),
deletionProtection: false,
databaseName: `demoProxiedDB`,
credentials: rds.Credentials.fromSecret(dbAuthSecret),
});
const proxy = database.addProxy("rdsProxy", {
secrets: [dbAuthSecret],
vpc: vpc,
vpcSubnets: {
subnetType: ec2.SubnetType.PRIVATE_ISOLATED,
},
securityGroups: [proxySecurityGroup],
});
Estos dos bloques son un poco más largos que los anteriores, pero solo hay un puñado de líneas que son dignas de mención. La mayoría es solo sobre hacer una instancia de base de datos muy barata y adjuntar el proxy:
- Cuando configuramos las subredes VPC, necesitamos especificar el tipo de subredes a las que queremos adjuntar tanto nuestra base de datos como el proxy. Porque nuestra red tiene solo subredes privadas aisladas, usamos
ec2.SubnetType.PRIVATE_ISOLATED - Podemos asociar múltiples grupos de seguridad tanto a la instancia RDS como al proxy. En este caso, solo seleccionamos el grupo de seguridad correspondiente para cada uno
- Para usar el secreto en nuestra instancia RDS, usamos la propiedad
credentialsy una llamada ards.Credentials.fromSecret. Para el proxy, solo pasamos el secreto al propsecrets
Creando nuestra Función Lambda
Escribiremos una sola función Lambda usando Python, destinada a servir solicitudes que vienen de la única URL disponible del API Gateway:
import logging
import psycopg2
from psycopg2.extras import RealDictCursor
import os
import boto3
import json
import sys
logger = logging.getLogger()
logger.setLevel("INFO")
db_host = os.environ['DB_ENDPOINT']
secret = os.environ['SECRET']
secrets_client = boto3.client("secretsmanager")
response = secrets_client.get_secret_value(SecretId=secret).get('SecretString')
secrets = json.loads(response)
try:
connection = psycopg2.connect(
database=secrets['dbname'],
user=secrets['username'],
password=secrets['password'],
host=db_host,
port='5432',
sslmode='require'
)
connection.autocommit = True
except psycopg2.Error as e:
logger.error(e)
sys.exit(1)
def handler(event, context):
with connection.cursor(cursor_factory=RealDictCursor) as cursor:
try:
query = """SELECT * FROM poke_data"""
cursor.execute(query)
return {'statusCode': 200,
'headers': {'content-type': 'application/json'},
'body': json.dumps(cursor.fetchall())}
except psycopg2.Error as err:
logger.error(err)
return {'statusCode': 500, 'body': "Error, check logs"}
def setup_db():
with connection.cursor(cursor_factory=RealDictCursor) as cursor:
try:
table_exists_query = """SELECT * FROM information_schema.tables
WHERE table_schema = current_schema()
AND table_name = 'poke_data'
"""
cursor.execute(table_exists_query)
table_exists = cursor.fetchone()
if not table_exists:
table_create_query = """CREATE TABLE poke_data (
dex_number INT,
name VARCHAR(255),
type VARCHAR(255)
);
"""
cursor.execute(table_create_query)
seed_query = """INSERT INTO poke_data
values
(1, 'Bulbasaur', 'Grass/Poison'),
(2, 'Ivysaur', 'Grass/Poison'),
(3, 'Venusaur', 'Grass/Poison'),
(4, 'Charmander', 'Fire');
"""
cursor.execute(seed_query)
except psycopg2.Error as err:
logger.error(err)
setup_db()
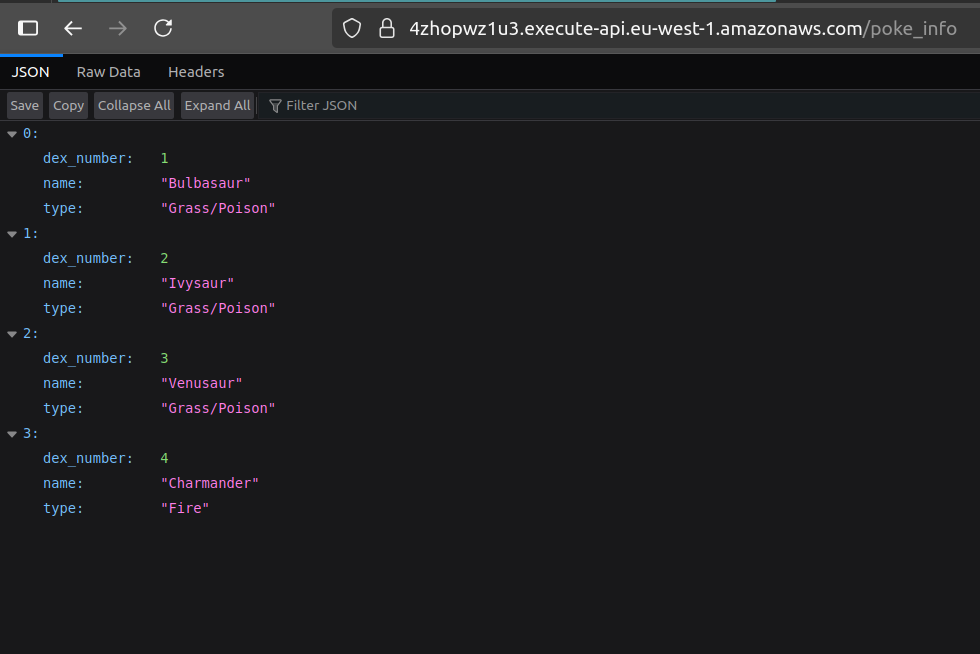
Esta función recupera algunas variables de entorno y las usa para recuperar el secreto con credenciales de base de datos, luego las usa para crear un cliente psycopg2. El handler de la función ejecuta una consulta muy simple (SELECT * FROM poke_data) y devuelve esos datos al la entidad que realiza la llamada—en este caso, el gateway mismo.
Hay otra función llamada setup_db que es responsable de crear la tabla respectiva y poblarla con algunos valores dummy. Este es un enfoque terrible y no debería replicarse en ningún otro lugar—es solo un hack muy conveniente para asegurar que este ejemplo funcione apropiadamente.
En el mundo real, tendrías varias opciones para elegir. Dos de las más razonables son:
- Usa el mecanismo de migración y seeding por defecto para tu plataforma. Si tu sistema usa, por ejemplo, imágenes de contenedor ejecutando Ruby on Rails, puedes usar los comandos por defecto
db:migrate,db:seed, odb:setuppara asegurar que la base de datos esté en forma de ejecución antes de servir solicitudes. Estos mecanismos usualmente son idempotentes y seguros, así que puedes hacer que su ejecución sea parte del paso de despliegue para tu solución. - Usa un recurso personalizado en CDK. Si no hay otras opciones, puedes definir de manera segura un recurso personalizado a cargo de ejecutar un script de configuración para tu base de datos y sembrarlo con algunos datos iniciales útiles. Este enfoque está mejor integrado con un flujo de trabajo IaC y es mucho más seguro que lo que intentamos en nuestra función Python.
Crear el código CDK para desplegar nuestra función es sencillo. Las únicas cosas dignas de mención son la instalación del módulo psycopg2 usando opciones de bundling, la adjunción del grupo de seguridad lambda, y el paso de variables de entorno con el endpoint del proxy y el nombre del secreto:
const pokeInfoFunction = new lambda.Function(this, "pokeFN", {
runtime: lambda.Runtime.PYTHON_3_13,
code: lambda.Code.fromAsset("lambdas", {
bundling: {
image: lambda.Runtime.PYTHON_3_13.bundlingImage,
command: [
"bash",
"-c",
"pip install --no-cache psycopg2-binary -t /asset-output && cp -au . /asset-output",
],
},
}),
timeout: cdk.Duration.seconds(30),
handler: "poke_list.handler",
vpc: vpc,
securityGroups: [lambdaSecurityGroup],
environment: {
DB_ENDPOINT: proxy.endpoint,
SECRET: dbAuthSecret.secretName,
},
description: "Provides a list of Pokémon for the pokeDataAPI API",
});
Creando el API Gateway
Este es solo una API HTTP simple con una sola integración Lambda:
const pokeDataAPI = new gateway.HttpApi(this, "pokeDataAPI");
pokeDataAPI.addRoutes({
path: "/poke_info",
methods: [gateway.HttpMethod.GET],
integration: new api_integrations.HttpLambdaIntegration(
"lpIntegration",
pokeInfoFunction
),
});
Permisos y Configuración Extra
Necesitamos dos cosas:
- Asegurar que la función Lambda tenga acceso de lectura al secreto.
- Crear una salida conveniente que nos muestre la URL de la API después del despliegue.
Lograr esto con CDK es muy fácil:
dbAuthSecret.grantRead(pokeInfoFunction);
new cdk.CfnOutput(this, "APIEndpoint", { value: pokeDataAPI.apiEndpoint });
Probando la Solución
Después de ejecutar cdk deploy, puedes visitar la ruta <base_url>/poke_info, donde base_url es cualquier valor de salida que APIEndpoint sea asignado cuando el despliegue se complete.
¡IMPORTANTE! Siempre recuerda eliminar tu stack ejecutando cdk destroy o eliminándolo manualmente en la consola.
Mejoras y Experimentos
- Trata de idear una mejor solución para configurar la base de datos después del despliegue, y saca esa lógica de la función Lambda
- Reproduce esta misma arquitectura, pero en lugar de adjuntar el proxy a la instancia primaria de una base de datos, trata de adjuntar el proxy a una réplica de lectura. ¿Es esto siquiera posible? ¿Por qué sería esto una buena o mala idea?
- Construye tu propio API Gateway respaldado por Lambda/RDS usando las herramientas que aprendiste en este laboratorio, y proporciona algunos recursos y acciones más al usuario.
El objetivo de este laboratorio fue enseñarte sobre una mentalidad común que tienes que adoptar cuando diseñas soluciones en la nube: Presta atención a las diferencias en cómo diferentes partes de tus sistemas pueden escalar hacia arriba o hacia abajo, y qué implicaciones pueden tener estas diferencias. Afortunadamente, la mayoría de los problemas que probablemente encuentres ya tienen una solución en forma de mejores prácticas o software especial que evita la limitación.
Aquí está la conclusión clave: siempre piensa sobre la escalabilidad y confiabilidad de tu sistema tanto a nivel de componente como en cómo esos componentes se hablan entre sí. Domina este enfoque, y te convertirás en un arquitecto mucho más efectivo mientras evitas toneladas de dolores de cabeza futuros.
¡Espero que esto te sea útil!