El código fuente para este artículo se puede encontrar aquí.
¡Bienvenido a otro experimento en la nube! La idea detrás de estos tutoriales prácticos es proporcionar experiencia práctica construyendo soluciones cloud-native de diferentes tamaños usando servicios de AWS y CDK. Nos enfocaremos en desarrollar experiencia en Infrastructure as Code, servicios de AWS y arquitectura en la nube mientras entendemos tanto el “cómo” como el “por qué” detrás de nuestras decisiones.
Una Pequeña Solución de Notificación Serverless
Esta vez, no estás tratando de resolver algún problema en el trabajo—solo quieres conseguir una nueva consola. El Nintendo Switch 2 se lanzó hace unas semanas, y como ya todos sabíamos, la demanda por la consola es mucho mayor que la cantidad de stock disponible.
La situación ahora mismo no es tan terrible, y parece haber un poco más de stock disponible en varios retailers online, pero realmente te gustaría poder conseguirla lo antes posible de una de las tiendas en tu área. Por eso, decidiste escribir un flujo de trabajo de notificación simple que te avise tan pronto como esté disponible.
El diseño se ve así:
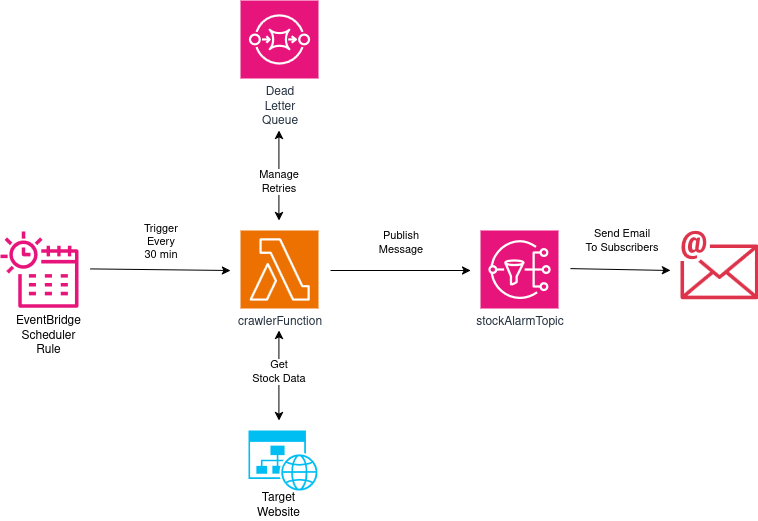
- Una regla EventBridge Scheduler disparará una función Lambda cada 30 minutos. Dos veces por hora es una frecuencia razonable—hoy en día ser notificado el mismo día que la consola esté disponible es más que suficiente.
- Las cosas podrían salir mal durante la ejecución de nuestra función, así que configuraremos una dead letter queue (DLQ) para mantener eventos fallidos por un poco, e instruir a nuestra función Lambda para hacer algunos reintentos antes de rendirse.
- Nuestra función Lambda recuperará HTML de la página del producto de la tienda online, e intentará descifrar si el producto está disponible o no basándose en eso.
- Si el producto está disponible, la función Lambda publicará un mensaje en un Topic SNS. Crearemos una suscripción de email (con nuestro propio email personal) para este topic SNS, así seremos notificados cuando se publiquen mensajes ahí.
Sabemos qué hacer, ¡así que empecemos a construir!
Creando nuestro Proyecto
El mismo procedimiento estándar de siempre: Primero, solo necesitamos crear una carpeta vacía (nombré la mía InventoryStockAlarm) y ejecutar cdk init app --language typescript dentro de ella.
Este siguiente cambio es totalmente opcional, pero lo primero que hago después de crear un nuevo proyecto CDK es dirigirme a la carpeta bin y renombrar el archivo app a main.ts. Luego abro el archivo cdk.json y edito la configuración app así:
{
"app": "npx ts-node --prefer-ts-exts bin/main.ts",
"watch": {
...
}
}
Ahora tu proyecto reconocerá main.ts como el archivo de aplicación principal. No tienes que hacer esto—solo me gusta tener un archivo llamado main sirviendo como archivo principal de la app.
Importaciones del Stack y Creando la Regla del Scheduler
Al mirar el diagrama, sabemos que necesitaremos las siguientes importaciones en la parte superior del stack:
import * as cdk from "aws-cdk-lib";
import { Construct } from "constructs";
import { aws_events as events } from "aws-cdk-lib";
import { aws_events_targets as event_targets } from "aws-cdk-lib";
import { aws_lambda as lambda } from "aws-cdk-lib";
import { aws_sns as sns } from "aws-cdk-lib";
import { aws_sqs as sqs } from "aws-cdk-lib";
import { aws_sns_subscriptions as sns_subs } from "aws-cdk-lib";
Crear una regla de programación usando CDK es fácil—la única propiedad que necesitaremos es un schedule para asegurar que emita un evento cada media hora, así:
const crawlingSchedule = new events.Rule(this, "crawlingSchedule", {
schedule: events.Schedule.rate(cdk.Duration.minutes(30)),
});
Creando el Topic SNS y una DLQ
Necesitaremos un topic SNS para recibir mensajes de la función Lambda, y reenviarlos a un email. También necesitaremos una cola SQS que nuestra función Lambda usará cuando una ejecución falle y necesite realizar reintentos.
Crearemos nuestro Topic SNS como:
const stockAlarmTopic = new sns.Topic(this, "stockAlarmTopic", {
topicName: "stockAlarmTopic",
displayName:
"SNS Topic to notify me by email if the product is available",
});
El topicName anula el comportamiento por defecto de asignar un nombre auto-generado al topic, lo que hace que encontrarlo sea más fácil. El displayName aparecerá en los emails que recibimos de este topic, como veremos más tarde cuando probemos nuestra solución.
Y luego creamos nuestra cola SQS:
const dlq = new sqs.Queue(this, "deadLetterQueue");
Crear este tipo de recurso usualmente es un esfuerzo muy simple—la mayor parte de la diversión viene de integrarlos con otros servicios, como haremos después.
Creando nuestra Función Lambda Crawler
Necesitamos una función Lambda que:
- Recupere datos de una URL dada
- Realice algún tipo de análisis en el HTML que recibe y descifre si el producto está disponible
- Si el producto está en stock, debería publicar un mensaje en un topic SNS
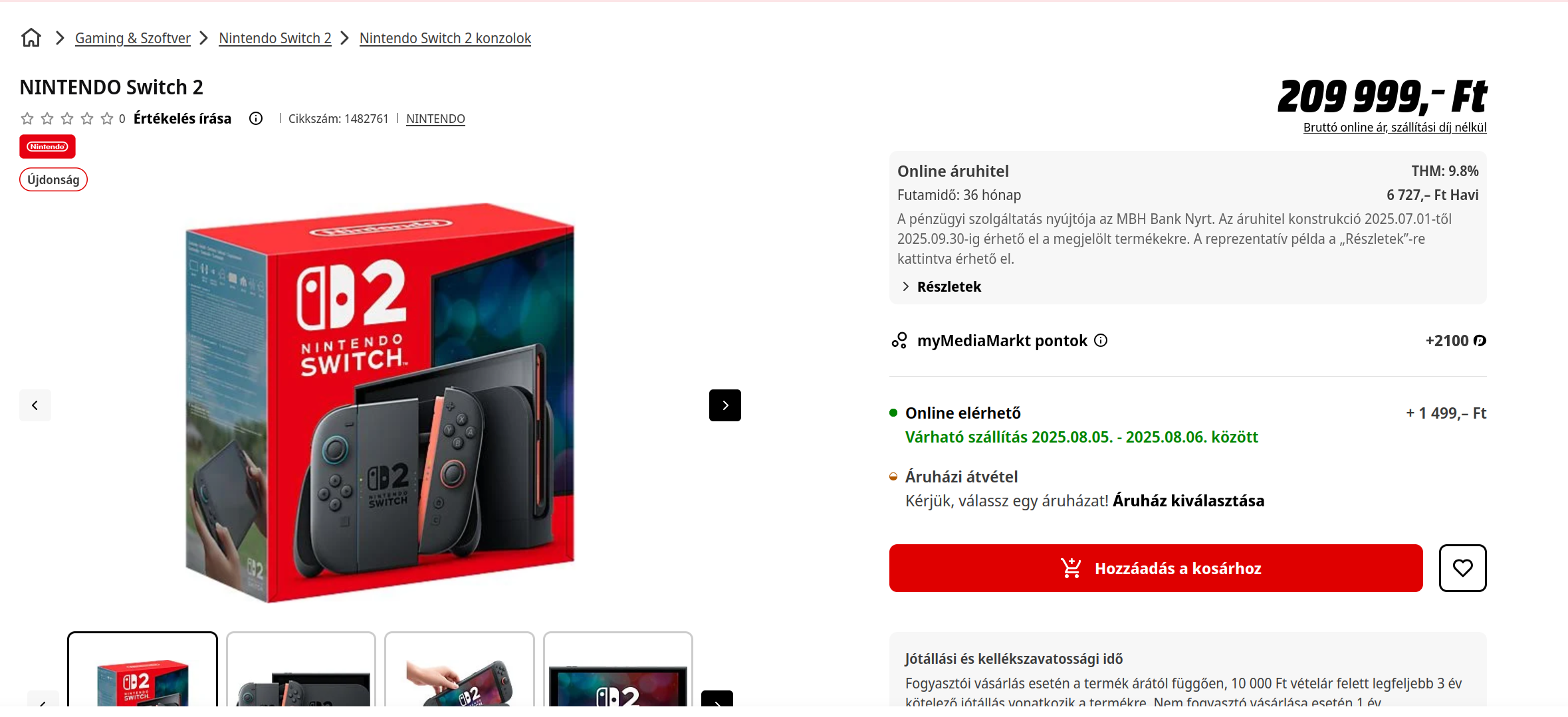
Estoy interesado en la disponibilidad de la consola en una tienda local, así que revisemos cómo se ve para productos disponibles y no disponibles. Descubrí que actualmente tienen stock para la consola Switch 2 estándar, y se ve así:
Para el bundle que viene con Mario Kart, obtenemos esto:
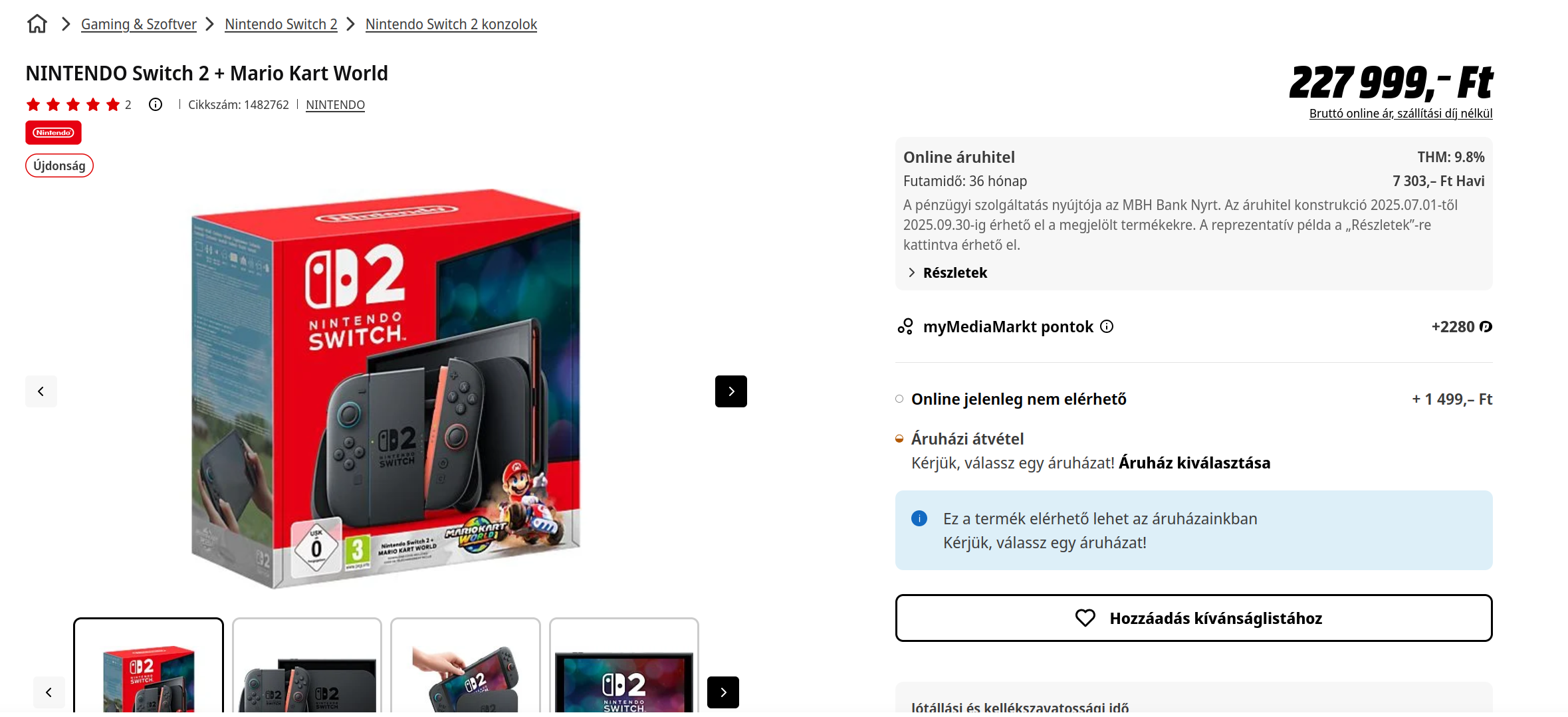
Puedes ver que la principal diferencia es la sección que dice Online elérhető (Disponible Online, en húngaro), así que probablemente deberíamos buscar esa cadena en el HTML que obtendremos de vuelta en nuestra solicitud.
Crea una carpeta llamada lambdas en el nivel raíz del proyecto (junto a bin y lib), y dentro crea un archivo llamado crawler.py:
import os
import requests
import boto3
from bs4 import BeautifulSoup
client = boto3.client('sns')
def handler(event, context):
product_url = os.environ.get('PRODUCT_URL')
availability_string = os.environ.get('AVAILABILITY_STRING')
sns_arn = os.environ.get('SNS_ARN')
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:141.0) Gecko/20100101 Firefox/141.0'
}
response = requests.get(product_url, headers=headers)
findings = BeautifulSoup(response.text, features="html.parser").findAll(string=availability_string)
if findings:
subject = "Product availability notice"
message = "The product is available!"
response = client.publish(
Message=message,
Subject=subject,
TargetArn=sns_arn,
)
Vamos sección por sección para entender qué hace:
- Importamos solo lo que necesitamos: El módulo
ospara recuperar variables de entorno, el módulorequestspara realizar una solicitud HTTP dirigida a una tienda online, el móduloboto3(el SDK de Python para AWS) para publicar un mensaje en el topic SNS, yBeautifulSouppara parsear HTML y buscar dentro de él. - Creamos un cliente SNS fuera del handler de la función—no queremos crear clientes en cada invocación Lambda, e instanciarlos fuera del handler nos permite compartir cualquier recurso o conexión a través de invocaciones mientras el entorno de ejecución permanezca caliente.
- De las variables de entorno tomamos la URL del producto, la cadena que escanearemos cuando tratemos de establecer si el producto está disponible (Online elérhető), y el ARN del topic SNS al que enviaremos mensajes si encontramos stock disponible.
- Realizamos una solicitud GET usando la URL del producto proporcionada, y pasamos un header con el user agent. Esto es importante porque la mayoría de sitios web bloquean instantáneamente solicitudes que carecen de un user agent de navegador para prevenir que crawlers recuperen datos (ejem). Luego usamos BeautifulSoup para escanear el HTML y descifrar si coincide con nuestra cadena de disponibilidad.
- Si hay un hallazgo (¡un match!) realizamos una llamada a la función
publishdel cliente, con un asunto y mensaje que serán parte del email enviado al usuario.
Tengo que notar que este es realmente, realmente mal código. El web crawling no es mi fuerte y la calidad de la función no es el punto de este laboratorio (la arquitectura y el diseño general lo son), pero es importante notar que esta probablemente no es la forma en que quieres proceder cuando construyes código para crawlear (vaya palabra) la web. El diseño es frágil; pequeños cambios en el sitio web, o usarlo en otro sitio definitivamente romperá el código, y no estamos manejando ninguna de las muchas excepciones que pueden surgir durante la ejecución. Vale la pena mencionarlo, pero no nos quedemos atascados en eso demasiado—sigamos adelante.
En nuestro stack podemos crear la función Lambda. Recuerda agregar opciones de bundling para instalar dependencias y pasar las variables de entorno necesarias para que la función opere apropiadamente.
const crawlerFunction = new lambda.Function(this, "crawlerFunction", {
runtime: lambda.Runtime.PYTHON_3_13,
code: lambda.Code.fromAsset("lambdas/crawler", {
bundling: {
image: lambda.Runtime.PYTHON_3_13.bundlingImage,
command: [
"bash",
"-c",
"pip install --no-cache requests beautifulsoup4 -t /asset-output && cp -au . /asset-output",
],
},
}),
handler: "crawler.handler",
timeout: cdk.Duration.seconds(30),
environment: {
PRODUCT_URL: props.productUrl,
AVAILABILITY_STRING: props.availabilityString,
SNS_ARN: stockAlarmTopic.topicArn,
},
description:
"Function for crawling a website in search of available stock",
});
crawlingSchedule.addTarget(
new event_targets.LambdaFunction(crawlerFunction, {
deadLetterQueue: dlq,
maxEventAge: cdk.Duration.minutes(20), // Set the maxEventAge retry to 20 minutes
retryAttempts: 2,
})
);
Nota que en la última sección de este bloque de código creamos un Lambda target para nuestro schedule. Con esto en su lugar, estaremos llamando nuestra función Lambda cada 30 minutos, y también configuramos la dead letter queue, establecemos el máximo reintento de edad del evento a 20 minutos, y limitamos el número de intentos de reintento a 2.
Creando una Suscripción de Email para nuestro Topic SNS
Necesitamos crear una suscripción que permita al topic enviarnos email. Esto es solo cuestión de llamar addSubscription en nuestro topic y agregar el email que queramos para recibir mensajes, así:
stockAlarmTopic.addSubscription(
new sns_subs.EmailSubscription(props.targetEmail)
);
Cuando el stack se despliegue por primera vez, recibiremos un email de confirmación que se ve así:

AWS se asegura de que las suscripciones SNS pasen por un proceso de dos pasos para asegurar que no estés suscribiendo maliciosamente direcciones de email desprevenidas a un topic que luego será usado para enviar spam. Solo necesitas hacer clic en Confirm Subscription, así AWS sabrá que esta es una suscripción legítima.
Props de Stack Personalizados
Hasta ahora, hemos estado referenciando algunos stack props que no están definidos en ningún lado (props.targetEmail, props.productUrl, y props.availabilityString), así que arreglemos eso.
En la parte superior de tu stack, antes de la definición de clase del stack, agrega la siguiente interfaz:
interface InventoryStockAlarmStackProps extends cdk.StackProps {
targetEmail: string;
productUrl: string;
availabilityString: string;
}
Luego, en la definición del constructor cambia el tipo de props de cdk.StackProps al que acabamos de crear, así:
constructor(
scope: Construct,
id: string,
props: InventoryStockAlarmStackProps
)
Agregando Permisos y Creando el Stack
Mi parte favorita de trabajar con CDK es probablemente lo fácil que es otorgar permisos a entidades dentro de AWS. Necesitamos:
- crawlerFunction debe poder publicar mensajes que apunten a stockAlarmTopic
En CDK, estos permisos se definen como:
stockAlarmTopic.grantPublish(crawlerFunction);
Y hemos terminado. Ahora podemos ir a main.ts y crear nuestro stack:
new InventoryStockAlarmStack(app, 'InventoryStockAlarmStack', {
targetEmail: 'jl.orozco.villa@gmail.com',
productUrl: 'https://www.mediamarkt.hu/hu/product/_nintendo-switch-2-mario-kart-world-1482762.html',
availabilityString: 'Online elérhető',
});
Decidí usar la URL para el bundle Mario Kart—actualmente no está disponible y me gustaría ser notificado tan pronto como esté disponible para compra online.
Probando el Stack
¡Eso es prácticamente todo! Ahora solo necesitas esperar hasta que el stock esté disponible y recibirás un email que se ve así:
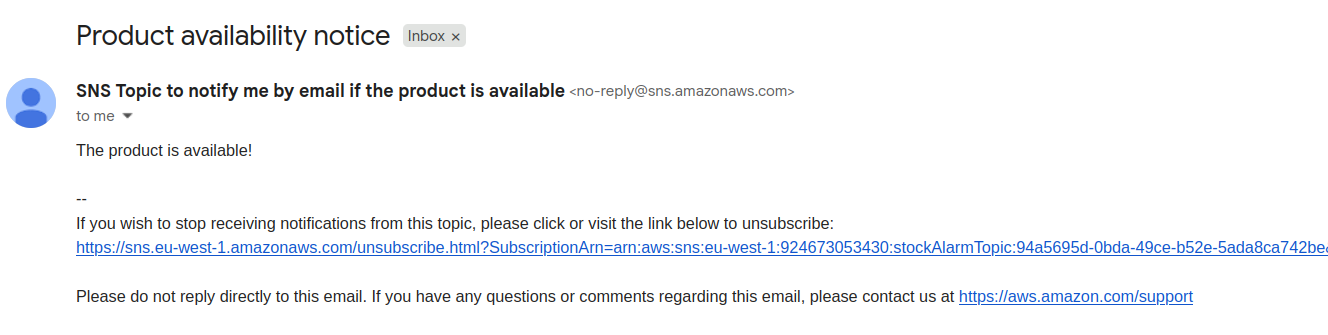
Luego, puedes ir y hacer un pedido para cualquier producto que estuvieras esperando.
¡IMPORTANTE! Siempre recuerda eliminar tu stack, ya sea ejecutando cdk destroy o eliminándolo manualmente en la consola.
Algunas Notas sobre Web Crawling
El web crawling es una práctica legal, pero dependiendo de las leyes y regulaciones que apliquen al lugar donde vives (copyright, términos de servicio, protección de datos) lo que decidas hacer con esos datos puede ser ilegal y terminará metiendote en problemas, así que siempre ten cautela.
Hay formas éticas de raspar (crawlear, raspar sonó como una traducción divertida) la web, así que en la medida de lo posible trata de respetar las guías del robots.txt de un sitio web, y aprende cómo hacerlo de la manera más conforme posible. Esto no es solo para que no te metas en problemas, sino que también es lo correcto.
Otra cosa importante a tener en cuenta es que dónde hospedas tus crawlers tiene un gran impacto en los resultados. La mayoría de tiendas tienen en su lugar algunas protecciones para asegurar que su sitio no sea crawleado por arañitas no deseados—a menudo ponen en lista negra la mayoría de rangos de IP de proveedores de nube para prevenirlos de enviar solicitudes a sus sitios, así que las posibilidades son que tus AWS Lambdas ni siquiera podrán acceder a la tienda sin hacer solicitudes a través de un proxy. La tienda que usé para este ejercicio fue parcialmente seleccionada por esta razón, ya que es un ejemplo de tal caso—las solicitudes que mi Lambda envió fueron en realidad bloqueadas (retornó un código 403), y tuve que hacer proxy de la solicitud para obtener la notificación que mostré al final.
El punto es, el web scraping es un campo grande con muchos matices y conocimiento especializado, y muchas personas se ganan la vida como constructores expertos en arañitas (título genial ahora que lo pienso, Juan L. Orozco V. CSO / Chief Spider Officer). Si estás interesado en el tema, hay algunos libros geniales por ahí, como el que tiene el Pangolín en la portada, que pueden darte el conocimiento que necesitas.
Mejoras y Experimentos
- En lugar de recibir una notificación por email, modifica el código para en su lugar enviarte un mensaje SMS.
- Aprende algo de web scraping, e intenta mejorar la función haciéndola más robusta.
- Actualmente, este stack solo puede monitorear una página de producto a la vez, así que propongo la siguiente modificación: En lugar de pasar la URL del producto y la cadena de disponibilidad como variables de entorno, recupera esas de eventos. Luego, crea eventos programados para consultar diferentes sitios web. Esto también requiere que modifiques el mensaje de notificación para listar el producto del que se trata la notificación.
- Ahora mismo, si un producto se vuelve disponible solo seguirá diciéndote sobre ello cada 30—esto puede volverse un poco molesto después de un tiempo. ¿Cómo abordarías prevenir esto? ¿Cómo puedes implementar un período de silencio después de que se encuentre stock por primera vez?
Esta vez tuvimos la oportunidad de jugar con topics SNS y EventBridge por primera vez. Mientras más servicios y constructs aprendas y domines, mejor te volverás diseñando y construyendo soluciones cloud-native—y este proyecto acaba de agregar dos nuevas herramientas valiosas a tu arsenal.
¡Espero que esto te sea útil!