El código fuente para este artículo se puede encontrar aquí.
¡Bienvenido a otro experimento en la nube! La idea detrás de estos tutoriales prácticos es proporcionar experiencia práctica construyendo soluciones cloud-native de diferentes tamaños usando servicios de AWS y CDK. Nos enfocaremos en desarrollar experiencia en Infrastructure as Code, servicios de AWS y arquitectura en la nube mientras entendemos tanto el “cómo” como el “por qué” detrás de nuestras decisiones.
Nota: Este laboratorio debe ser estudiado junto con un laboratorio complementario que muestra una manera alternativa de lograr el mismo objetivo. La sección introductoria es la misma, pero vale la pena contrastar la manera en que ambos stacks son construidos.
Hospedando Contenedores en un Entorno Serverless
Docker (y otras tecnologías de contenedores como Podman) son increíbles. Hacen que el empaquetado y despliegue de software sea mucho más fácil, así que no es sorpresa que los contenedores se hayan convertido en un formato común y ampliamente soportado para compartir y desplegar aplicaciones. Hay muchas alternativas diferentes para ejecutar contenedores, desde despliegues completos de Kubernetes hasta solo ejecutar algunos contenedores en una máquina virtual, como una pequeña instancia EC2.
AWS te permite hacer ambas cosas, pero también ofrece una manera simplificada de ejecutar contenedores—tanto en máquinas virtuales como en un entorno serverless—a través del Elastic Container Service (ECS). En este laboratorio, aprenderemos cómo crear un servicio ECS simple con balanceador de carga ejecutándose en la plataforma de contenedores serverless de AWS, Fargate.
La arquitectura de nuestra solución se verá así:
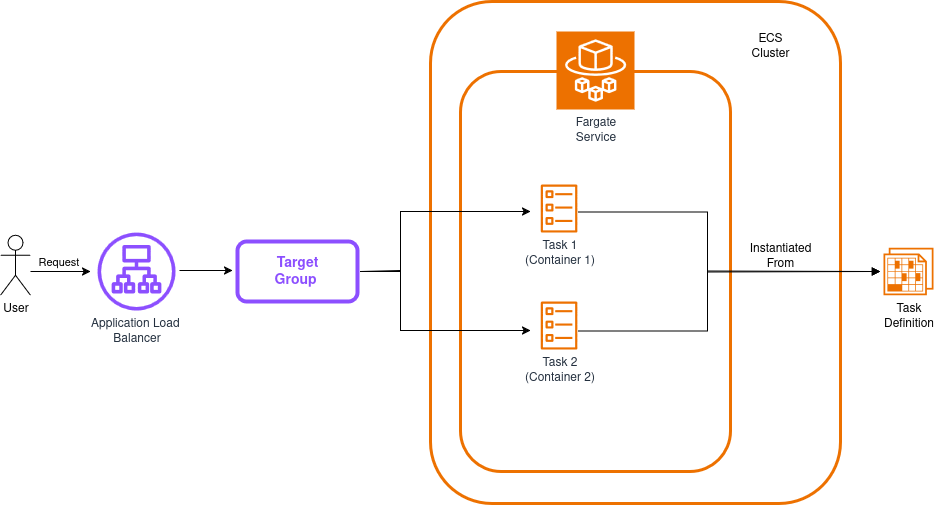
Antes de proceder, es importante revisar algunos conceptos relevantes, al menos a un nivel superficial:
-
Load Balancer: Un componente que distribuye el tráfico entrante a través de múltiples objetivos con el fin de esparcir la carga uniformemente entre ellos. Usaremos un Application Load Balancer para este laboratorio, pero AWS también proporciona un Network Load Balancer y el load balancer clásico (principalmente para usos legacy).
-
Target Group: Una colección de recursos que reciben tráfico reenviado por el load balancer. Estos usualmente son contenedores, máquinas virtuales, funciones Lambda, o básicamente casi cualquier cosa a la que puedas adjuntar una IP. Los load balancers pueden tener múltiples target groups.
-
ECS Cluster: Una colección de recursos de computación que servirán como la fundación sobre la que tus contenedores se ejecutarán. Puedes hacer que sea un cluster respaldado por EC2 o usar el entorno serverless Fargate.
-
ECS Fargate Service: Un tipo de servicio que puedes agregar a tu cluster que se ejecuta en un entorno serverless. Este servicio es responsable de asegurar que un número dado de tareas de un tipo dado estén ejecutándose en un estado saludable dentro de tu cluster.
-
ECS Task: Las tareas son básicamente contenedores. Bueno, no necesariamente, porque una sola tarea puede tener definiciones para más de un contenedor (como una aplicación contenedor más un contenedor de logging/métricas ejecutándose al lado), pero puedes pensar en ellas como contenedores o colecciones de contenedores.
-
ECS Task Definition: Esta es un plano que contiene instrucciones para construir tus tareas. Si has hecho programación orientada a objetos, puedes pensar en las task definitions como clases y las tareas como instancias.
Nuestra app ejecutará dos tareas (cada una con un solo contenedor) y distribuirá solicitudes entre ellas para mejorar la resistencia y rendimiento—un patrón común en despliegues en la nube. El diagrama de arriba omite los grupos de seguridad, que bloquean acceso directo a contenedores mientras aún permiten que el load balancer reenvíe tráfico. Ten en cuenta que nuestro stack creará estos recursos automáticamente.
¡Genial! Con una mejor idea de dónde encaja todo, ¡estamos listos para empezar a construir nuestra solución!
Construyendo la Aplicación de Prueba
Necesitamos una aplicación que podamos contenerizar para probar nuestro stack—ojalá algo simple. Crearemos una pequeña aplicación Sinatra con una sola ruta (la raíz) y una sola vista que imprima algunos datos básicos únicos para cada contenedor.
Crea una carpeta llamada app, y dentro de ella crea un Gemfile con estos contenidos:
source 'https://rubygems.org'
gem 'sinatra'
gem 'rackup'
gem 'puma'
Ahora podemos crear el archivo principal de la app. Junto al Gemfile, crea app.rb:
# frozen_string_literal: true
require 'sinatra'
set :port, 4567
set :bind, '0.0.0.0'
get '/' do
@container_hostname = ENV['HOSTNAME']
erb :index
end
Este archivo usa una vista (index), así que el siguiente paso es crear una carpeta llamada views (dentro de la carpeta app), y dentro de ella crear un archivo llamado index.erb:
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Test Sinatra App</title>
</head>
<body style="font-family: 'Times New Roman';">
<div style="text-align: center; line-height: 100px;">
<h2>Test Sinatra App</h2>
<% if @container_hostname %>
<p>Serving content from: <%= @container_hostname %></p>
<% end %>
</div>
</body>
</html>
Ahora, el último paso es escribir un Dockerfile para construir la imagen docker de nuestra aplicación:
# Dockerfile
FROM ruby:3.3
ENV APP_ENV=production
WORKDIR /app
COPY . /app
RUN bundle install
EXPOSE 4567
CMD ["ruby", "app.rb"]
¡Y hemos terminado! La estructura de carpetas debería verse así:
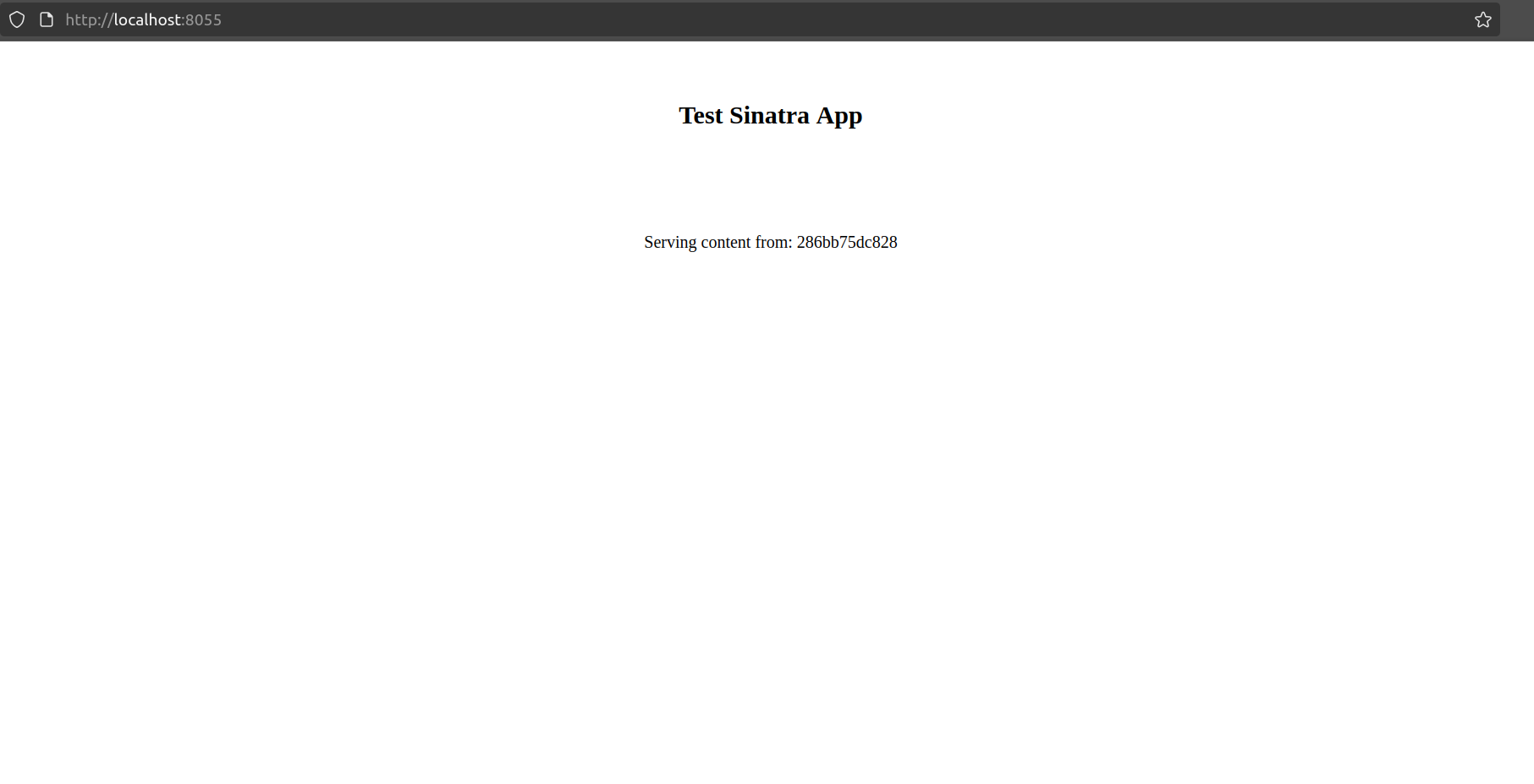
Puedes escribir la app tú mismo o solo copiarla del repositorio del laboratorio. No necesitas probarla localmente, pero si quieres darle una pequeña prueba, solo ejecuta el comando docker build --tag 'sample-sinatra' . para crear la imagen del contenedor, y luego ejecútala con docker run -p 8055:4567 sample-sinatra. Esto servirá la app en tu localhost en el puerto 8055, así:
Hemos terminado con la app—ahora podemos enfocarnos en la infraestructura.
Construyendo nuestro Stack
Creación del Proyecto
Primero, necesitamos la configuración regular del proyecto a la que nos hemos acostumbrado.
Crea una carpeta vacía (nombré la mía LoadBalancedECSFargateFromPattern) y ejecuta cdk init app --language typescript dentro de ella.
Este siguiente cambio es opcional, pero lo primero que hago después de crear un nuevo proyecto CDK es dirigirme a la carpeta bin y renombrar el archivo app a main.ts. Luego abro el archivo cdk.json y edito la configuración app:
{
"app": "npx ts-node --prefer-ts-exts bin/main.ts",
"watch": {
...
}
}
Ahora tu proyecto reconocerá main.ts como el archivo de aplicación principal. No tienes que hacer esto—solo me gusta tener un archivo llamado main sirviendo como archivo principal de la app.
Importaciones del Stack
Al mirar el diagrama, sabemos que necesitaremos las siguientes importaciones en la parte superior del stack:
import * as cdk from 'aws-cdk-lib';
import {Construct} from 'constructs';
import {aws_ecs as ecs} from "aws-cdk-lib";
import {aws_ecs_patterns as ecs_patterns} from "aws-cdk-lib";
Crear el Stack
¿Recuerdas todo el trabajo que hicimos para construir la solución en el laboratorio complementario? Esta vez, puedes lograr exactamente lo mismo con solo lo siguiente:
const fargateService = new ecs_patterns.ApplicationLoadBalancedFargateService(
this,
"fargateService",
{
taskImageOptions: {
image: ecs.ContainerImage.fromAsset('app'),
containerPort: 4567,
},
desiredCount: 2,
memoryLimitMiB: 1024,
minHealthyPercent: 100,
}
);
Eso es todo—ese es el stack completo. ¡Esto creará y configurará los mismos recursos que creamos en el laboratorio anterior, con mucho menos código! Creo que es útil tener constructs que implementen patrones tan comunes, y cuando sea posible, siempre trata de ir por la solución más simple y limpia.
Tu caso de uso puede diferir de lo que es alcanzable con estos patrones, pero es mucho más fácil empezar con una solución simple y ganar conocimiento sobre el dominio y entorno, y luego usar este conocimiento para refinar una solución potencialmente más complicada, que hacer lo opuesto.
Probando la Solución
Para este, el procedimiento de prueba es el mismo que seguimos en el laboratorio complementario. Puedes solo repetir los pasos que seguimos ahí.
¡IMPORTANTE! Siempre recuerda eliminar tu stack ejecutando cdk destroy o eliminándolo manualmente en la consola.
Mejoras y Experimentos
-
Echa un vistazo a otros patrones, como
ApplicationMultipleTargetGroupsEc2ServiceyQueueProcessingFargateService. Piensa sobre qué casos de uso pueden beneficiarse de estas configuraciones y escribe tus propias soluciones. -
Como en el otro laboratorio, el mejor y probablemente más fructífero experimento que puedes intentar es usar este laboratorio como fundación para contenerizar y desplegar tu propia aplicación.
Casi siempre hay más de una manera de lograr un objetivo, y se pueden ganar ideas valiosas explorando diferentes enfoques. Cada método lleva sus propias fortalezas y debilidades, y estudiándolos, puedes juzgar mejor cuál es más probable que se alinee con los requisitos complejos y restricciones del problema a la mano.
Espero que comparar estas dos soluciones te ayude a elegir el mejor enfoque para tu próximo proyecto centrado en contenedores. O, siempre podrías tirar todo a Kubernetes… y esperar lo mejor.
¡Espero que esto te sea útil!