El código fuente para este artículo se puede encontrar aquí.
¡Bienvenido a otro experimento en la nube! La idea detrás de estos tutoriales prácticos es proporcionar experiencia práctica construyendo soluciones cloud-native de diferentes tamaños usando servicios de AWS y CDK. Nos enfocaremos en desarrollar experiencia en Infrastructure as Code, servicios de AWS y arquitectura en la nube mientras entendemos tanto el “cómo” como el “por qué” detrás de nuestras decisiones.
Un Pipeline para Procesar PDFs
Tu empresa ha lanzado una nueva iniciativa para extraer valor adicional de los PDFs generados por sistemas de sus clientes. El plan es construir un pipeline que extraiga información relevante de estos archivos y la use para entrenar un modelo de machine learning, o algo así. La gerencia realmente no sabe cómo va a proceder, pero aun así te han elegido para diseñar y construir las primeras secciones del pipeline. ¡Felicitaciones!
Sabemos que queremos construir un pipeline serverless para transformar archivos PDF en una serie de imágenes PNG (una por página) y extraer el texto de cada página. Trabajaremos a nivel de página a lo largo del pipeline, lo que significa dividir el PDF en representaciones de páginas individuales mientras mantenemos la trazabilidad al archivo original.
Podemos crear una solución usando solo buckets S3 y funciones Lambda. Aquí está nuestra arquitectura:
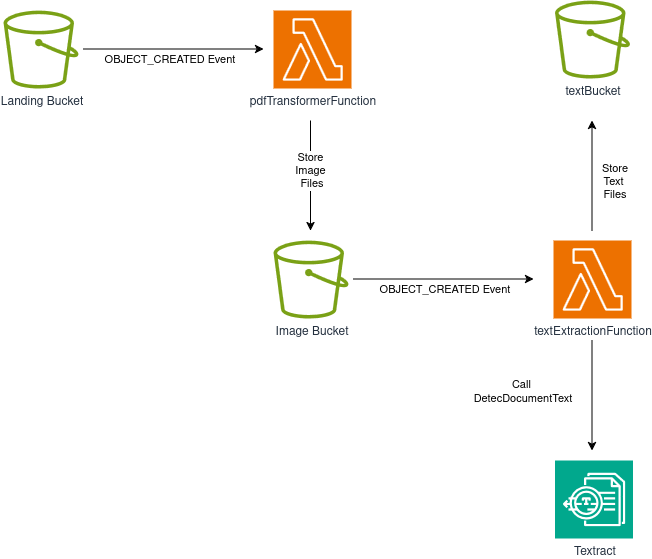
El flujo es el siguiente:
- Un bucket S3 sirve como nuestro bucket de aterrizaje y punto de entrada para el flujo de trabajo. Las aplicaciones cliente u otros componentes del sistema pueden subir archivos PDF aquí.
- El bucket de aterrizaje usa Notificaciones de Eventos S3 para disparar una función Lambda cada vez que se crea un objeto. Esta función divide el PDF en páginas individuales y convierte cada página en una imagen PNG, almacenando los resultados en nuestro bucket de imágenes.
- El bucket de imágenes emite eventos cuando se crean objetos (¡igual que nuestro bucket de aterrizaje!), disparando una segunda función Lambda que extrae texto de cada imagen PNG.
- La función Lambda de extracción de texto llama AWS Textract para realizar OCR en las imágenes del bucket de imágenes. El texto extraído se guarda entonces en nuestro bucket de texto.
El flujo de trabajo es directo y nos da una gran oportunidad de trabajar con múltiples servicios de AWS y obtener algo de experiencia práctica con los SDKs de S3 y Textract. ¡Empecemos!
Creando nuestro Proyecto
Solo necesitamos crear una carpeta vacía (nombré la mía ServerlessPdfProcessingPipeline) y ejecutar cdk init app --language typescript dentro de ella.
Este siguiente cambio es totalmente opcional, pero lo primero que hago después de crear un nuevo proyecto CDK es dirigirme a la carpeta bin y renombrar el archivo app a main.ts. Luego abro el archivo cdk.json y edito la configuración app así:
{
{
"app": "npx ts-node --prefer-ts-exts bin/main.ts",
"watch": {
...
}
Ahora tu proyecto reconocerá main.ts como el archivo de aplicación principal. No tienes que hacer esto, solo me gusta tener un archivo llamado main sirviendo como archivo principal de la app.
Creando nuestros Buckets
Ahora puedes abrir el archivo dentro de la carpeta lib y ¡empezar a construir tu stack! Primero, agrega las importaciones necesarias en la parte superior:
import * as cdk from "aws-cdk-lib";
import { Construct } from "constructs";
import { aws_s3 as s3 } from "aws-cdk-lib";
import { aws_lambda as lambda } from "aws-cdk-lib";
import { aws_s3_notifications as s3n } from "aws-cdk-lib";
import { aws_iam as iam } from "aws-cdk-lib";
Estamos usando importaciones V2, es un poco más limpio de esta manera. Ahora creemos nuestros buckets S3, necesitaremos:
- Un bucket de aterrizaje, para archivos PDF, y sirviendo como punto de entrada para nuestro sistema.
- Un bucket de imágenes, para representaciones PNG de cada página en un PDF.
- Un bucket de texto, conteniendo texto extraído para cada página en formato TXT.
Construir estos recursos es bastante fácil, solo necesitamos agregar las siguientes líneas a nuestro constructor:
constructor(
scope: Construct,
id: string,
props?: cdk.StackProps
) {
super(scope, id, props);
const landingBucket = new s3.Bucket(this, "landingBucket", {
removalPolicy: cdk.RemovalPolicy.DESTROY,
autoDeleteObjects: true,
});
const imageBucket = new s3.Bucket(this, "imageBucket", {
removalPolicy: cdk.RemovalPolicy.DESTROY,
autoDeleteObjects: true,
});
const textBucket = new s3.Bucket(this, "textBucket", {
removalPolicy: cdk.RemovalPolicy.DESTROY,
autoDeleteObjects: true,
});
Nota que estamos configurando cada bucket para ser destruido automáticamente si eliminamos nuestro stack. Esto está bien si planeamos desplegar este pipeline en un entorno de desarrollo o staging, pero deberíamos evitar esto en entornos de producción. Si nos preocupan los costos de almacenamiento, podemos en su lugar configurar nuestros buckets con una política de Lifecycle para remover objetos después de una cantidad determinada de tiempo o moverlos a una clase de almacenamiento más barata.
Computación Serverless Usando Funciones Lambda
Necesitamos escribir dos funciones lambda, una para dividir un archivo PDF en imágenes PNG, y una para extraer texto de cada imagen.
Crea una carpeta llamada lambdas en el nivel raíz del proyecto (junto a bin y lib), luego crea dos carpetas:
- pdf_to_image
- text_extractor
Cada carpeta contendrá los assets para su respectiva función lambda.
Extrayendo Texto
Escribamos la función de extracción de texto primero, es un poco más fácil. Usaremos Ruby para esta, con el fin de obtener suficiente práctica usando el AWS SDK con diferentes lenguajes. Dentro de la carpeta text_extractor, crea un archivo llamado text_extractor.rb:
# frozen_string_literal: true
require 'aws-sdk-s3'
require 'cgi'
require 'aws-sdk-textract'
TEXTRACT = Aws::Textract::Client.new
S3 = Aws::S3::Client.new
def handler(event:, context:)
bucket = event['Records'][0]['s3']['bucket']['name']
key = CGI.unescape(event['Records'][0]['s3']['object']['key'])
text_bucket_name = ENV['TEXT_BUCKET_NAME']
response = TEXTRACT.detect_document_text(
{
document: {
s3_object: {
bucket: bucket,
name: key
}
}
}
)
text_content = response.data
.blocks
.select { |b| b.block_type == 'LINE' }
.map(&:text)
.join("\n")
S3.put_object(
bucket: text_bucket_name,
key: "#{File.basename key, '.png'}.txt",
body: text_content
)
end
Nota los siguientes detalles:
- Estamos definiendo los clientes para S3 y TEXTRACT fuera del handler. Esto es una buena práctica estándar cuando se trabaja con Lambdas porque maximiza el rendimiento: El código definido fuera del handler permanecerá activo para futuras invocaciones dentro del entorno de ejecución lambda mientras esté todavía “caliente”.
- Dentro del handler, buscamos entre los contenidos del evento para encontrar el nombre del bucket, y la key (nombre del archivo) para el objeto que procesaremos. Estamos pasando el nombre del bucket objetivo como una variable de entorno.
- Realizamos una llamada a la API TEXTRACT y obtenemos de vuelta una respuesta que contiene información extraída del archivo al que apunta. Nota que no pasamos los contenidos de la imagen, solo apuntamos textract al bucket y objeto (archivo) que queremos procesar. Esto es parte de la conveniencia ganada de la interoperabilidad de AWS. Porque solo nos importan los bloques que contienen texto, filtramos y formateamos solo aquellos con el tipo LINE.
- Finalmente, almacenamos nuestro texto en el bucket objetivo (nuestro bucket de texto) usando una llamada put_object.
Dividiendo un PDF en Imágenes PNG
Con el objetivo de tener un mejor aprendizaje, usemos Python para la siguiente función. Crea pdf_to_image_transformer.py en la carpeta pdf_to_image:
import boto3
import botocore.exceptions
import io
import os
import logging
import urllib
from pdf2image import convert_from_bytes
s3 = boto3.resource('s3')
logger = logging.getLogger()
logger.setLevel("INFO")
def handler(event, context):
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
image_bucket_name = os.environ.get('IMAGE_BUCKET_NAME')
target_dpi = int(os.environ.get('TARGET_DPI'))
# Perform image conversion, 1 page -> 1 image
pdf_file = bytes(s3.Object(bucket, key).get()['Body'].read())
images = convert_from_bytes(pdf_file, dpi=target_dpi, fmt="png",)
key_without_extension, _ = os.path.splitext(key)
# Store each image on S3
for count, image in enumerate(images):
try:
buffer = io.BytesIO()
image.save(buffer, format=image.format)
s3_object = s3.Object(
image_bucket_name, f"{key_without_extension}_page{count+1}.png")
s3_object.put(Body=buffer.getvalue())
except botocore.exceptions.ClientError as e:
logger.error(e)
No hay mucho que destacar sobre la función, el código es bastante sencillo: Recibimos un evento, usamos esa información para recuperar el archivo PDF y procesarlo usando la función convert_from_bytes de pdf2image para transformar cada página en una imagen, y luego almacenar esas imágenes en S3.
Lo más notable sobre esta función lambda es el uso de pdf2image, que no está incluido en el runtime Python lambda por defecto. En un artículo anterior aprendimos cómo manejar dependencias Python en entornos lambda usando la opción bundling, pero desafortunadamente esta vez no nos ayudará.
¿Por qué?
Porque pdf2image depende del paquete poppler-utils, e instalar ese archivo usando la misma técnica resulta ser un verdadero dolor de cabeza. No hay problema, tenemos otra solución fácil para este problema: Crear una imagen docker con las dependencias (tanto el paquete poppler-utils como el módulo pdf2image) y desplegar la lambda usando esa imagen.
Junto a tu archivo python, crea otro archivo llamado requirements.txt:
pdf2image==1.17.0
Después, crea un tercer archivo y llámalo Dockerfile:
FROM public.ecr.aws/lambda/python:3.13
# Copy function code
COPY pdf_to_image_transformer.py ${LAMBDA_TASK_ROOT}
# Install additional system dependencies
RUN dnf install poppler-utils -y
# Install Python dependencies
COPY requirements.txt ${LAMBDA_TASK_ROOT}
RUN pip install -r requirements.txt
# Set the CMD to your handler (could also be done as a parameter override outside of the Dockerfile)
CMD [ "pdf_to_image_transformer.handler" ]
Este Dockerfile instala poppler-utils usando dnf, copia todos los archivos requeridos, instala las dependencias Python, y establece el punto de entrada para la Lambda.
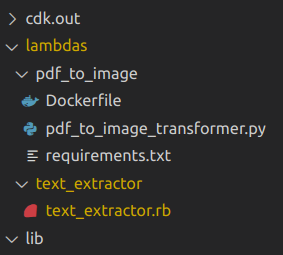
La estructura de tu carpeta lambdas ahora debería verse así:
Hemos terminado con los contenidos de nuestras funciones lambda. Regresa a tu archivo stack en la carpeta lib y agrega estas definiciones de funciones Lambda:
//... antes de esto, definimos nuestros buckets
const pdfTransformerFunction = new lambda.DockerImageFunction(
this,
"pdfTransformFunction",
{
code: lambda.DockerImageCode.fromImageAsset("lambdas/pdf_to_image"),
environment: {
TARGET_DPI: String(props.targetDpi),
IMAGE_BUCKET_NAME: imageBucket.bucketName,
},
description: "Transforms a PDF into images, one per page",
memorySize: 512,
timeout: cdk.Duration.seconds(120),
}
);
const textExtractionFunction = new lambda.Function(
this,
"textExtractionFunction",
{
runtime: lambda.Runtime.RUBY_3_3,
code: lambda.Code.fromAsset("lambdas/text_extractor"),
handler: "text_extractor.handler",
environment: {
TEXT_BUCKET_NAME: textBucket.bucketName,
},
description: "Extracts text from each image that gets created",
timeout: cdk.Duration.seconds(120),
}
);
Usamos diferentes constructs para cada función: DockerImageFunction para nuestro procesador PDF contenedorizado (vaya palabra) y una Function estándar para el extractor de texto Ruby. Ambas funciones tienen timeouts configurados y descripciones, con el transformador PDF obteniendo memoria extra ya que la manipulación de imágenes puede ser consumir más recursos.
Nos gustaría tener más control sobre la calidad de las imágenes producidas durante la transformación, y para eso necesitamos hacer el DPI configurable. Primero, crea una interfaz props en la parte superior de tu archivo:
interface ServerlessPdfProcessingPipelineStackProps extends cdk.StackProps {
targetDpi: number;
}
Y luego cambia la signatura prop del constructor para aceptar un objeto de este tipo en lugar del cdk.StackProps regular, así:
props: ServerlessPdfProcessingPipelineStackProps
Ya hemos terminado con la mayor parte del trabajo. ¡Ahora configuremos la emisión de eventos en los buckets S3, y establezcamos las funciones como sus objetivos!
Configurando Eventos S3
Esta parte es bastante directa:
landingBucket.addEventNotification(
s3.EventType.OBJECT_CREATED,
new s3n.LambdaDestination(pdfTransformerFunction),
{ suffix: ".pdf" }
);
imageBucket.addEventNotification(
s3.EventType.OBJECT_CREATED,
new s3n.LambdaDestination(textExtractionFunction),
{ suffix: ".png" }
);
Para cada bucket, configuramos eventos OBJECT_CREATED para disparar la función Lambda apropiada, usando filtros de sufijo para asegurar que los eventos solo se disparen para los tipos de archivo correctos.
Agregando Permisos y Creando el Stack
Mi parte favorita de trabajar con CDK es probablemente lo fácil que es otorgar permisos a entidades dentro de AWS. Necesitamos:
- pdfTransformerFunction debe poder leer del landingBucket
- pdfTransformerFunction debe poder escribir al imageBucket
- textExtractionFunction debe poder leer del imageBucket
- textExtractionFunction debe poder escribir al textBucket
- textExtractionFunction debe poder llamar DetectDocumentText en el servicio Textract
En CDK, estos permisos se definen como:
landingBucket.grantRead(pdfTransformerFunction);
imageBucket.grantWrite(pdfTransformerFunction);
imageBucket.grantRead(textExtractionFunction);
textBucket.grantWrite(textExtractionFunction);
// Allow the text extraction lambda function to query the TEXTRACT API
const textractPolicy = new iam.PolicyStatement({
actions: ["textract:DetectDocumentText"],
resources: ["*"],
});
textExtractionFunction.addToRolePolicy(textractPolicy);
Y hemos terminado. Ahora podemos ir a main.ts y crear nuestro stack:
const app = new cdk.App();
new ServerlessPdfProcessingPipelineStack(app, 'ServerlessPdfProcessingPipelineStack', { // O cualquier nombre de clase que se le haya dado a tu stack
targetDpi: 300,
});
¡Ejecutar cdk deploy construirá nuestro proyecto, creará nuestra imagen lambda, y desplegará nuestro stack directamente en AWS!
Probando el Stack
Después del despliegue, navega a S3 y localiza tu bucket de aterrizaje (tendrá un nombre generado largo como serverlesspdfprocessingpipel-landingbucket72c76a11-dkggauhw4bwe). Sube un archivo PDF—elige algo de tamaño razonable ya que tu Lambda puede carecer de recursos para archivos muy grandes.
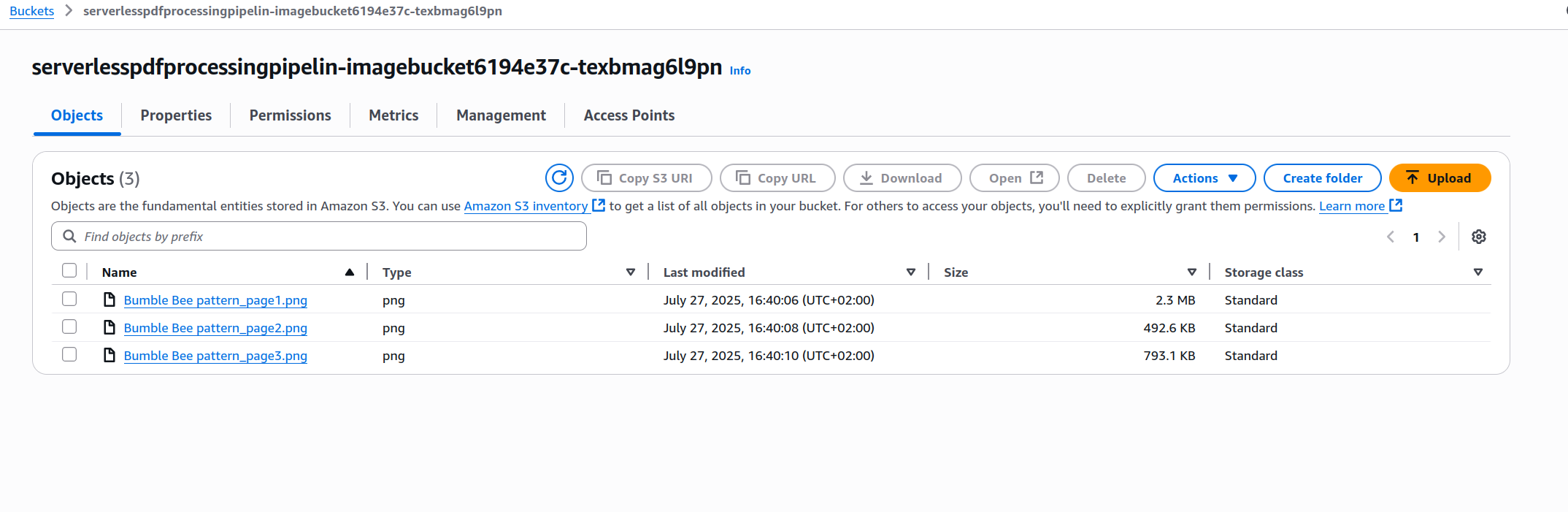
Usé un patrón de crochet escrito por mi esposa, tiene tres páginas con imágenes e instrucciones para hacer pequeñas abejas amigurumi. Después de esperar unos segundos fui e inspeccioné los buckets de imagen y texto y encontré esto:
-
Bucket de Imágenes
-
Bucket de Texto
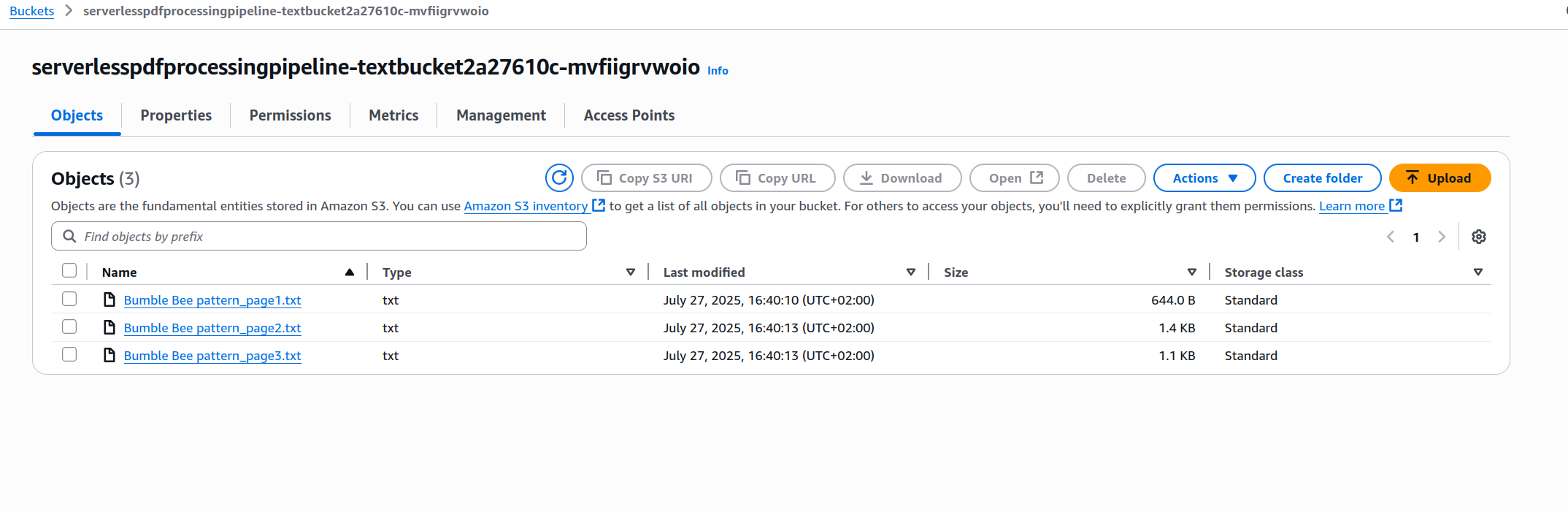
Los contenidos corresponden perfectamente a cada página en el PDF original.
¡IMPORTANTE! Siempre recuerda eliminar tu stack, ya sea ejecutando cdk destroy o eliminándolo manualmente en la consola.
Mejoras y Experimentos
- Nuestra función usa
detect_document_texten imágenes, pero Textract también ofrecestart_document_text_detectionpara procesamiento PDF asíncrono. ¿Cómo cambiaría el usar esta función nuestra arquitectura? ¿Tiene sentido que se dispare al mismo tiempo que lo hace ahora? - Con representaciones de texto del contenido PDF, ¿cómo podrías implementar moderación o filtrado de contenido? ¿Qué servicios podrían ayudar con esto?
- ¿Podríamos simplificar la funcionalidad PDF-a-PNG usando un runtime diferente? ¿Qué probarías en lugar de Python y Docker?
- Experimenta con diferentes valores de
targetDpi(75, 100, 200, 400, 600). ¿Cómo afectan los cambios al tiempo de ejecución de la función y la precisión de extracción de texto? ¿Puedes encontrar un balance óptimo entre costo y calidad? - Ahora que tenemos la primera parte del pipeline en su lugar, ¿qué tipo de análisis o procesamiento adicional es posible, y cómo lo lograrías?
- ¿Es posible enviar los eventos del bucket a una cola SQS en lugar de pasarlos directamente a cada función lambda? ¿Cuáles son las ventajas y desventajas de este enfoque?
Aprendemos mejor cuando jugamos con un sistema y probamos diferentes cosas, así que no tengas miedo de inventar tus propios experimentos y modificaciones.
¡Lo hicimos! Terminamos nuestro primer experimento en la nube, y obtuvimos un poco más de experiencia práctica trabajando con soluciones cloud-native.
¡Espero que esto te sea útil!