El código fuente para este artículo se puede encontrar aquí.
¡Bienvenido a otro experimento en la nube! La idea detrás de estos tutoriales prácticos es proporcionar experiencia práctica construyendo soluciones cloud-native de diferentes tamaños usando servicios de AWS y CDK. Nos enfocaremos en desarrollar experiencia en Infrastructure as Code, servicios de AWS y arquitectura en la nube mientras entendemos tanto el “cómo” como el “por qué” detrás de nuestras decisiones.
Un Flujo de Trabajo de Moderación Serverless
En un proyecto anterior, construimos un pipeline para procesar archivos PDF a diferentes formatos usando solo S3, Lambda y Textract.
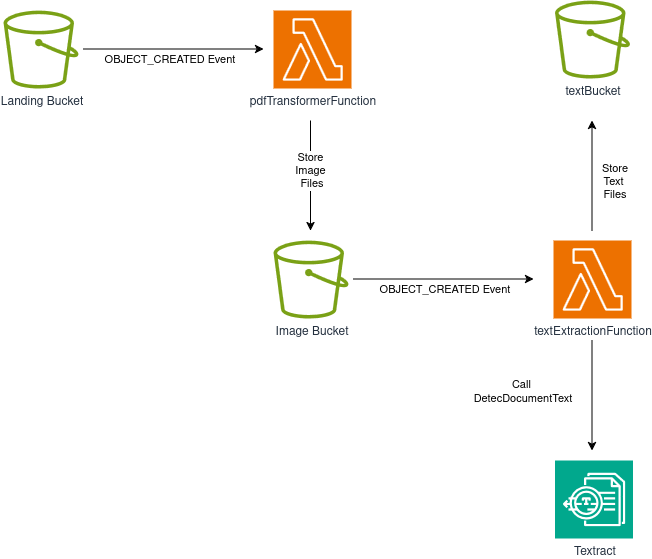
El proyecto fue un gran éxito, ¡y tanto la gerencia como el equipo de Data/ML estuvieron muy contentos con los artefactos producidos por el pipeline!
Ahora que saben que eres bastante bueno en esto de la nube, han empezado a preguntarse si puedes ayudar con otro problema que afecta una parte diferente del sistema: contenido dañino generado por usuarios.
La empresa actualmente le da soporte a una plataforma que permite a los clientes subir y compartir archivos PDF con otros usuarios, y les gustaría automatizar la eliminación de archivos que contienen material dañino o gráfico. Creen que podrías usar tu proyecto anterior como base para construir una solución a este problema.
Después de tiempo considerando opciones, terminas con el siguiente diseño:
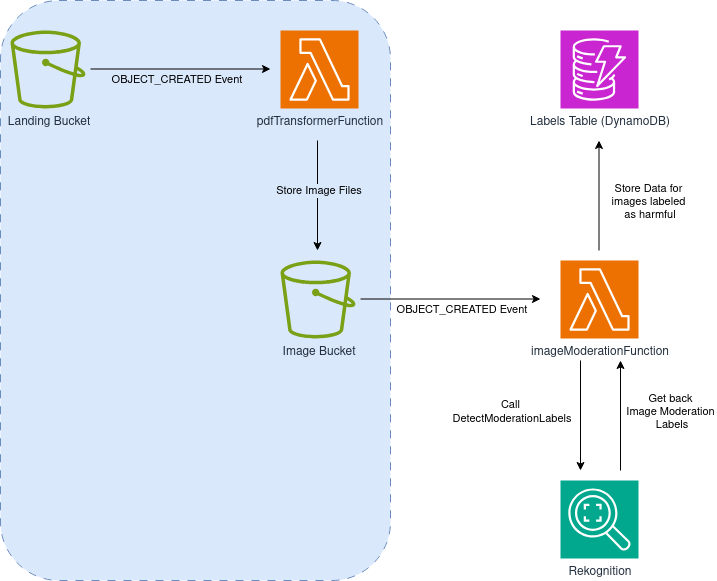
Nota que la sección izquierda de la solución (fondo azul claro) es idéntica a los primeros pasos del pipeline de procesamiento de PDF que construimos antes, así que enfoquémonos en lo que es nuevo:
- Después de que un archivo PDF es subido al bucket de aterrizaje y transformado en imágenes individuales (una por página), los eventos OBJECT_CREATED generados por el bucket de Imágenes serán enviados a una nueva función Lambda: imageModerationFunction
- Nuestra imageModerationFunction realizará una llamada
DetectModerationLabelsal servicio Rekognition - Si se detecta una etiqueta consistente con contenido dañino, crearemos una entrada en una tabla DynamoDB que llamaremos labelsTable
Parece bastante directo, ¡así que empecemos a construirlo!
Creando nuestro Proyecto
El mismo procedimiento estándar de siempre: Primero, solo necesitamos crear una carpeta vacía (nombré la mía ServerlessPdfContentModerationPipeline) y ejecutar cdk init app --language typescript dentro de ella.
Este siguiente cambio es totalmente opcional, pero lo primero que hago después de crear un nuevo proyecto CDK es dirigirme a la carpeta bin y renombrar el archivo app a main.ts. Luego abro el archivo cdk.json y edito la configuración app así:
{
{
"app": "npx ts-node --prefer-ts-exts bin/main.ts",
"watch": {
...
}
Ahora tu proyecto reconocerá main.ts como el archivo de aplicación principal. No tienes que hacer esto, solo me gusta tener un archivo llamado main sirviendo como archivo principal de la app.
Importaciones del Stack y Construyendo el Transformador PDF a PNG
Al mirar el diagrama, sabemos que necesitaremos las siguientes importaciones:
import * as cdk from "aws-cdk-lib";
import { Construct } from "constructs";
import { aws_s3 as s3 } from "aws-cdk-lib";
import { aws_lambda as lambda } from "aws-cdk-lib";
import { aws_dynamodb as dynamo } from "aws-cdk-lib";
import { aws_s3_notifications as s3n } from "aws-cdk-lib";
import { aws_iam as iam } from "aws-cdk-lib";
Después, reproduciremos los mismos constructs que usamos en nuestro transformador PDF-a-PNG anterior. No hay necesidad de entrar en detalle con esta sección, así que simplemente peguemos el código que teníamos y notemos algunos detalles clave:
interface ServerlessPdfContentModerationPipelineStackProps
extends cdk.StackProps {
targetDpi: number;
minimum_moderation_confidence: number;
}
export class ServerlessPdfContentModerationPipelineStack extends cdk.Stack {
constructor(
scope: Construct,
id: string,
props: ServerlessPdfContentModerationPipelineStackProps
) {
super(scope, id, props);
const landingBucket = new s3.Bucket(this, "landingBucket", {
removalPolicy: cdk.RemovalPolicy.DESTROY,
autoDeleteObjects: true,
});
const imageBucket = new s3.Bucket(this, "imageBucket", {
removalPolicy: cdk.RemovalPolicy.DESTROY,
autoDeleteObjects: true,
});
const labelsTable = new dynamo.Table(this, "pageModerationLabels", {
partitionKey: {
name: "filepage",
type: dynamo.AttributeType.STRING,
},
tableName: "pageModerationLabels",
removalPolicy: cdk.RemovalPolicy.DESTROY,
});
const pdfTransformerFunction = new lambda.DockerImageFunction(
this,
"pdfTransformFunction",
{
code: lambda.DockerImageCode.fromImageAsset("lambdas/pdf_to_image"),
environment: {
TARGET_DPI: String(props.targetDpi),
IMAGE_BUCKET_NAME: imageBucket.bucketName,
},
description: "Transforms a PDF into images, one per page",
memorySize: 512,
timeout: cdk.Duration.seconds(120),
}
);
Nota: Si no has completado el laboratorio anterior, te animo a regresar y echar un vistazo para entender cómo logramos la transformación de documentos PDF en imágenes PNG
- El nombre del stack es diferente esta vez.
- Definimos nuestras propias propiedades del stack usando una interfaz. Pasamos dos parámetros:
targetDpi, tal como hicimos antes, y uno nuevo llamadominimum_moderation_confidence. Este último parámetro será usado por la nueva función lambda para filtrar etiquetas de moderación por debajo del umbral de confianza proporcionado. - También estamos definiendo una tabla DynamoDB llamada pageModerationLabels. Nota que establecemos la partition key y configuramos la política de eliminación para asegurar que la tabla será destruida cuando desmontemos el stack, así que ten cuidado sobre las implicaciones de esto para entornos de producción—¡no quieres perder tus valiosos datos!
Creando nuestra Lambda de Etiquetas de Moderación
Para esta, usaremos Ruby.
En la carpeta lambdas, crea una nueva subcarpeta llamada image_moderation, y dentro de ella crea un archivo llamado image_moderation.rb. El código para esta función lambda es el siguiente:
# frozen_string_literal: true
require 'aws-sdk-rekognition'
require 'aws-sdk-dynamodb'
require 'cgi'
REKOGNITION = Aws::Rekognition::Client.new
DYNAMO = Aws::DynamoDB::Client.new
def handler(event:, context:)
bucket = event['Records'][0]['s3']['bucket']['name']
key = CGI.unescape(event['Records'][0]['s3']['object']['key'])
table_name = ENV['DYNAMO_TABLE_NAME']
minimum_confidence = ENV['MIN_CONFIDENCE'].to_f
resp = REKOGNITION.detect_moderation_labels(
{ image: {
s3_object: {
bucket: bucket,
name: key
}
},
min_confidence: minimum_confidence }
)
moderation_labels = resp.moderation_labels.map { |l| { name: l.name, confidence: l.confidence } }
return if moderation_labels.empty?
DYNAMO.put_item({
table_name: table_name,
item: { filepage: key, labels: moderation_labels }
})
end
Vamos a desglosarlo:
- Fuera del handler, hacemos nuestras importaciones y creamos un cliente para interactuar con el servicio Rekognition, y uno para interactuar con nuestra tabla DynamoDB.
- Nuestro handler recupera el bucket y la key (nombre del archivo) del evento emitido desde S3. Luego, obtenemos el nombre de nuestra tabla y el umbral mínimo de confianza de las variables de entorno pasadas a nuestra función—agregaremos esas a nuestro stack pronto.
- Después, realizamos una llamada a la función
detect_moderation_labelsusando el cliente Rekognition. No necesitamos descargar la imagen y pasarla como datos binarios; solo necesitamos apuntar al bucket y archivo en el que estamos haciendo la detección como parámetros. También pasamos un parámetro opcional llamado min_confidence para asegurar que solo obtenemos etiquetas de moderación por encima del umbral deseado—no estamos interesados en cada posible etiqueta de moderación, solo en las que tienen más probabilidad de representar el contenido de cada página. Después de eso, hacemos un poco de selección de datos para el nombre de cada etiqueta y su nivel de confianza. - Si no hay etiquetas de moderación disponibles, asumimos que la página/imagen es segura y simplemente retornamos. De lo contrario, realizamos una llamada al servicio DynamoDB (
put_item) para escribir las etiquetas a nuestra tabla, usando el nombre del archivo como la clave y las etiquetas de moderación como contenido.
Ahora podemos regresar a nuestro stack y agregar lo siguiente:
const imageModerationFunction = new lambda.Function(
this,
"imageModerationFunction",
{
runtime: lambda.Runtime.RUBY_3_3,
code: lambda.Code.fromAsset("lambdas/image_moderation"),
handler: "image_moderation.handler",
environment: {
MIN_CONFIDENCE: String(props.minimum_moderation_confidence),
DYNAMO_TABLE_NAME: labelsTable.tableName,
},
description:
"Uses Rekognition to detect harmful content, and stores results on a DynamoDB table",
timeout: cdk.Duration.seconds(30),
}
);
Configurando Eventos S3
Ahora solo necesitamos asegurar que los eventos OBJECT_CREATED de cada bucket lleguen a la función correcta. Eso se puede lograr fácilmente agregando esta pequeña sección a nuestro stack:
landingBucket.addEventNotification(
s3.EventType.OBJECT_CREATED,
new s3n.LambdaDestination(pdfTransformerFunction),
{ suffix: ".pdf" }
);
imageBucket.addEventNotification(
s3.EventType.OBJECT_CREATED,
new s3n.LambdaDestination(imageModerationFunction),
{ suffix: ".png" }
);
Agregando Permisos y Creando el Stack
Como siempre, agregar permisos usando CDK es muy fácil. Necesitamos:
- pdfTransformerFunction debe poder leer del landingBucket
- pdfTransformerFunction debe poder escribir al imageBucket
- imageModerationFunction debe poder leer del imageBucket
- imageModerationFunction debe poder escribir a labelsTable
- imageModerationFunction debe poder llamar DetectModerationLabels en el servicio Rekognition
En CDK, estos permisos se definen como:
// Permisos de lectura/escritura de bucket y tabla para las funciones
landingBucket.grantRead(pdfTransformerFunction);
imageBucket.grantWrite(pdfTransformerFunction);
imageBucket.grantRead(imageModerationFunction);
labelsTable.grantWriteData(imageModerationFunction);
// Igual para la otra lambda, pero con Rekognition
const rekognitionPolicy = new iam.PolicyStatement({
actions: ["rekognition:DetectModerationLabels"],
resources: ["*"],
});
imageModerationFunction.addToRolePolicy(rekognitionPolicy);
Y hemos terminado. Es hora de dirigirse a main.ts y crear nuestro stack:
new ServerlessPdfContentModerationPipelineStack(app, 'ServerlessPdfContentModerationPipelineStack', {
targetDpi: 300,
minimum_moderation_confidence: 60,
});
Decidí usar un umbral de confianza de moderación de 60. El valor correcto depende del tipo de contenido que tu aplicación verá y qué tipo de requisitos necesitas satisfacer. Encontrar un buen valor se trata de balancear la proporción de falsos positivos y falsos negativos que estás dispuesto a tolerar, y eso usualmente necesita un poco de experimentación.
Probando el Stack
Después del despliegue, navega a S3 y localiza tu bucket de aterrizaje (tendrá un nombre generado largo como serverlesspdfcontentmoderati-landingbucket72c76a11-use2yo9mxnka). Sube un archivo PDF—elige algo de tamaño razonable ya que tu Lambda puede carecer de recursos para archivos muy grandes.
Creé cuatro archivos de prueba para probar la solución:
- normal_doc: Documento normal, no tiene nada fuera de lo ordinario y sirve como línea base para las pruebas.
- hate_doc: Igual que nuestro doc normal, pero con un símbolo de odio insertado en la página 3.
- lewd_doc: Igual que nuestro doc normal, pero con un retrato de una mujer en topless en la página 3.
- tobacco_doc: Igual que nuestro doc normal, pero con una imagen de una persona fumando en la página 2.
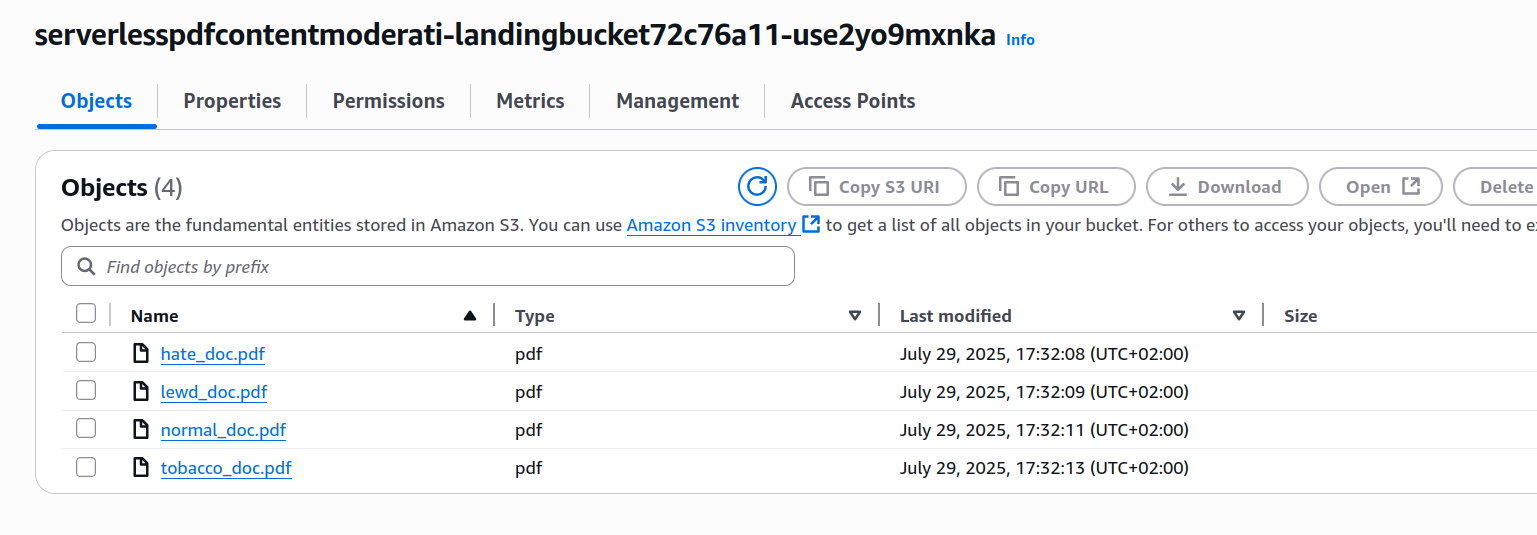
Subí los 4 archivos al bucket de aterrizaje y esperé unos segundos, luego me dirigí al panel DynamoDB e inspeccioné los contenidos de mi tabla.
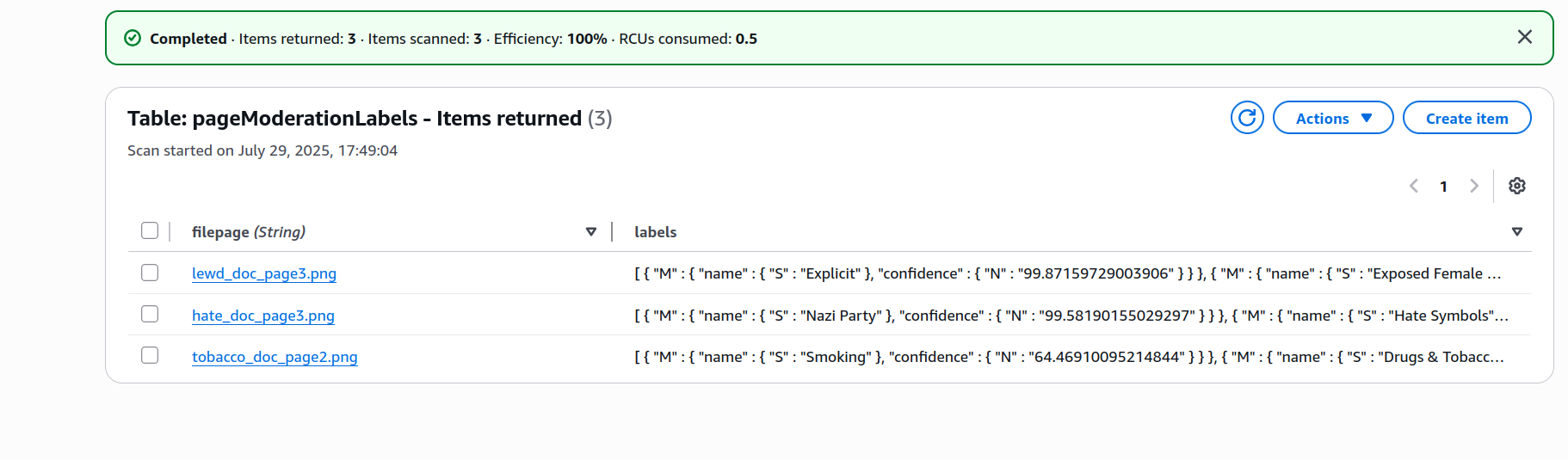
Si inspeccionas las etiquetas asignadas a, digamos, el tobacco_doc, encontrarás datos con esta estructura:
[
{
"M": {
"name": { "S": "Smoking" },
"confidence": { "N": "64.46910095214844" }
}
},
{
"M": {
"name": { "S": "Drugs & Tobacco Paraphernalia & Use" },
"confidence": { "N": "64.46910095214844" }
}
},
{
"M": {
"name": { "S": "Drugs & Tobacco" },
"confidence": { "N": "64.46910095214844" }
}
}
]
Está funcionando bastante bien—asignó etiquetas a todos los documentos con contenido que típicamente querrías moderar en algunas plataformas, mientras dejó fuera normal_doc. También puedes notar que el clasificador se siente más confiado sobre las etiquetas para los otros documentos de lo que se siente sobre las que asignó a tobacco_doc.
¡IMPORTANTE! Siempre recuerda eliminar tu stack, ya sea ejecutando cdk destroy o eliminándolo manualmente en la consola.
Mejoras y Experimentos
- ¿Sería posible combinar nuestro pipeline de moderación y la funcionalidad de extracción de texto que construimos antes? ¿Cómo diseñarías e implementarías esta solución conjunta?
- ¿Por qué es importante dejar detalles como
targetDpio el umbral de confianza como valores configurables fuera de nuestro stack? ¿Qué ventajas obtienes de esto? - Ahora que tenemos la primera parte del pipeline en su lugar, ¿qué tipo de análisis o procesamiento adicional es posible, y cómo lo lograrías? DynamoDB también puede emitir eventos en respuesta a cambios dentro de sus tablas—¿cómo puedes capitalizar eso para extender el flujo de trabajo?
- ¿Es posible enviar los eventos del bucket a una cola SQS en lugar de enviarlos directamente a cada función lambda? ¿Cuáles son las ventajas y desventajas de este enfoque?
- Hemos estado usando la misma sección al principio del pipeline para dos proyectos. Puede ser una buena idea crear un construct personalizado incluyendo los primeros dos buckets, la lambda de transformación de formato, y todos los permisos requeridos y configuraciones de eventos. Inténtalo, y piensa sobre qué debería exponer la interfaz de este construct al mundo exterior.
Con eso, ¡logramos completar nuestro segundo experimento en la nube! Mientras más experimentas y construyes, mejor entiendes el ecosistema de la nube y cómo construir soluciones usando una variedad de herramientas y servicios, así que no tengas miedo de inventar tus propios experimentos y modificaciones.
¡Espero que esto te sea útil!