The source code for this article can be found here.
Welcome to another cloud experiment! The idea behind these hands-on tutorials is to provide practical experience building cloud-native solutions of different sizes using AWS services and CDK. We’ll focus on developing expertise in Infrastructure as Code, AWS services, and cloud architecture while understanding both the “how” and “why” behind our choices.
A Serverless Moderation Workflow
In a previous project, we built a pipeline for processing PDF files into different formats using only S3, Lambda, and Textract.
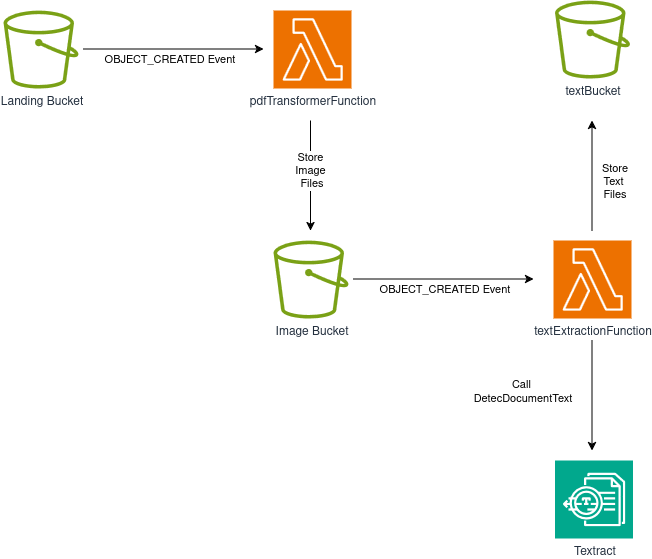
The project was a huge success, and both management and the Data/ML team were very happy with the artifacts produced by the pipeline!
Now that they know you’re quite good at this cloud thing, they’ve started wondering if you can help with another problem affecting a different part of the system: harmful user-generated content.
The company currently supports a platform that lets customers upload and share PDF files with other users, and would like to automate the removal of files that contain harmful or graphic material. They believe you could use your previous project as a foundation for building a solution to this problem.
After some consideration, you come up with the following design:
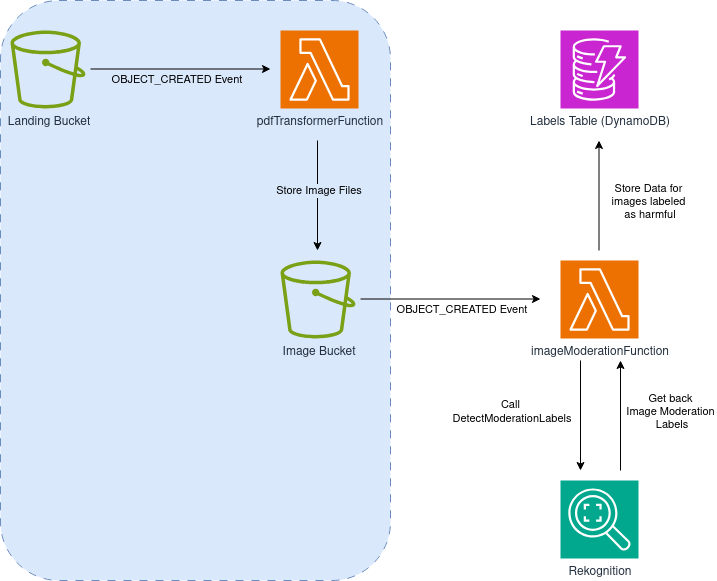
Note that the left section of the solution (light-blue background) is identical to the first few steps of the PDF processing pipeline we built before, so let’s focus on what’s new:
- After a PDF file is uploaded to the landing bucket and transformed into individual images (one per page), OBJECT_CREATED events generated by the Image bucket will be sent to a new Lambda function: imageModerationFunction
- Our imageModerationFunction will perform a
DetectModerationLabelscall to the Rekognition service - If a label consistent with harmful content is detected, we’ll create an entry in a DynamoDB table we’ll call labelsTable
Seems quite straightforward, so let’s start building it!
Creating our Project
Same old standard procedure: First, we just need to create an empty folder (I named mine ServerlessPdfContentModerationPipeline) and run the cdk init app --language typescript inside it.
This next change is totally optional, but the first thing I do after creating a new CDK project is to head into the bin folder and rename the app file to main.ts. Then I open the cdk.json file and edit the app config like this:
{
{
"app": "npx ts-node --prefer-ts-exts bin/main.ts",
"watch": {
...
}
Now your project will recognize main.ts as the main application file. You do not have to do this, I just like having a file named main serving as main app file.
Stack Imports and Building the PDF to PNG Transformer
From looking at the diagram, we know we’ll need the following imports:
import * as cdk from "aws-cdk-lib";
import { Construct } from "constructs";
import { aws_s3 as s3 } from "aws-cdk-lib";
import { aws_lambda as lambda } from "aws-cdk-lib";
import { aws_dynamodb as dynamo } from "aws-cdk-lib";
import { aws_s3_notifications as s3n } from "aws-cdk-lib";
import { aws_iam as iam } from "aws-cdk-lib";
Next, we’ll reproduce the same constructs we used in our previous PDF-to-PNG transformer. There’s no need to go into detail with this section, so let’s just paste the code we had and note a few key details:
interface ServerlessPdfContentModerationPipelineStackProps
extends cdk.StackProps {
targetDpi: number;
minimum_moderation_confidence: number;
}
export class ServerlessPdfContentModerationPipelineStack extends cdk.Stack {
constructor(
scope: Construct,
id: string,
props: ServerlessPdfContentModerationPipelineStackProps
) {
super(scope, id, props);
const landingBucket = new s3.Bucket(this, "landingBucket", {
removalPolicy: cdk.RemovalPolicy.DESTROY,
autoDeleteObjects: true,
});
const imageBucket = new s3.Bucket(this, "imageBucket", {
removalPolicy: cdk.RemovalPolicy.DESTROY,
autoDeleteObjects: true,
});
const labelsTable = new dynamo.Table(this, "pageModerationLabels", {
partitionKey: {
name: "filepage",
type: dynamo.AttributeType.STRING,
},
tableName: "pageModerationLabels",
removalPolicy: cdk.RemovalPolicy.DESTROY,
});
const pdfTransformerFunction = new lambda.DockerImageFunction(
this,
"pdfTransformFunction",
{
code: lambda.DockerImageCode.fromImageAsset("lambdas/pdf_to_image"),
environment: {
TARGET_DPI: String(props.targetDpi),
IMAGE_BUCKET_NAME: imageBucket.bucketName,
},
description: "Transforms a PDF into images, one per page",
memorySize: 512,
timeout: cdk.Duration.seconds(120),
}
);
Note: If you have not completed the previous lab, I encourage you to go back and take a look to understand how we accomplish the transformation of PDF documents into PNG images
- The stack name is different this time.
- We defined our own stack properties using an interface. We pass two parameters:
targetDpi, just as we did before, and a new one namedminimum_moderation_confidence. This last parameter will be used by the new lambda function to filter moderation labels below the provided confidence threshold. - We’re also defining a DynamoDB table called pageModerationLabels. Note that we set the partition key and configure the removal policy to ensure the table will be destroyed when we tear down the stack, so be mindful about the implications of this for production environments—you don’t want to lose your valuable data!
Creating our Moderation Labels Lambda
For this one, we will use Ruby.
In the lambdas folder, create a new subfolder named image_moderation, and within it create a file named image_moderation.rb. The code for this lambda function is as follows:
# frozen_string_literal: true
require 'aws-sdk-rekognition'
require 'aws-sdk-dynamodb'
require 'cgi'
REKOGNITION = Aws::Rekognition::Client.new
DYNAMO = Aws::DynamoDB::Client.new
def handler(event:, context:)
bucket = event['Records'][0]['s3']['bucket']['name']
key = CGI.unescape(event['Records'][0]['s3']['object']['key'])
table_name = ENV['DYNAMO_TABLE_NAME']
minimum_confidence = ENV['MIN_CONFIDENCE'].to_f
resp = REKOGNITION.detect_moderation_labels(
{ image: {
s3_object: {
bucket: bucket,
name: key
}
},
min_confidence: minimum_confidence }
)
moderation_labels = resp.moderation_labels.map { |l| { name: l.name, confidence: l.confidence } }
return if moderation_labels.empty?
DYNAMO.put_item({
table_name: table_name,
item: { filepage: key, labels: moderation_labels }
})
end
Let’s break it down:
- Outside of the handler, we do our imports and create a client for interacting with the Rekognition service, and one for interacting with our DynamoDB table.
- Our handler retrieves the bucket and key (filename) from the event emitted from S3. Then, we get the name of our table and the minimum confidence threshold from environment variables passed into our function—we’ll add those to our stack soon.
- Next, we perform a call to the
detect_moderation_labelsfunction using the Rekognition client. We don’t need to download the image and pass it as binary data; we just need to point to the bucket and file we’re doing the detection on as parameters. We also pass an optional parameter called min_confidence to ensure we only get moderation labels above a desired threshold—we’re not interested in every possible moderation label, just the ones more likely to represent the content of each page. After that, we do a bit of data selection for the name of each label and its confidence level. - If no moderation labels are available, we assume the page/image is safe and just return. Otherwise, we perform a call to the DynamoDB service (
put_item) to write the labels to our table, using the name of the file as the key and the moderation labels as content.
Now we can go back to our stack and add the following:
const imageModerationFunction = new lambda.Function(
this,
"imageModerationFunction",
{
runtime: lambda.Runtime.RUBY_3_3,
code: lambda.Code.fromAsset("lambdas/image_moderation"),
handler: "image_moderation.handler",
environment: {
MIN_CONFIDENCE: String(props.minimum_moderation_confidence),
DYNAMO_TABLE_NAME: labelsTable.tableName,
},
description:
"Uses Rekognition to detect harmful content, and stores results on a DynamoDB table",
timeout: cdk.Duration.seconds(30),
}
);
Configuring S3 Events
Now we just need to ensure OBJECT_CREATED events from each bucket reach the right function. That can easily be accomplished by adding this small section to our stack:
landingBucket.addEventNotification(
s3.EventType.OBJECT_CREATED,
new s3n.LambdaDestination(pdfTransformerFunction),
{ suffix: ".pdf" }
);
imageBucket.addEventNotification(
s3.EventType.OBJECT_CREATED,
new s3n.LambdaDestination(imageModerationFunction),
{ suffix: ".png" }
);
Adding Permissions and Creating the Stack
As always, adding permissions using CDK is very easy. We need:
- pdfTransformerFunction must be able to read from landingBucket
- pdfTransformerFunction must be able to write to imageBucket
- imageModerationFunction must be able to read from imageBucket
- imageModerationFunction must be able to write to labelsTable
- imageModerationFunction must be able to call DetectModerationLabels on the Rekognition service
In CDK, these permissions are defined as:
// Bucket and table read/write permissions for the functions
landingBucket.grantRead(pdfTransformerFunction);
imageBucket.grantWrite(pdfTransformerFunction);
imageBucket.grantRead(imageModerationFunction);
labelsTable.grantWriteData(imageModerationFunction);
// Same for the other lambda, but with Rekognition
const rekognitionPolicy = new iam.PolicyStatement({
actions: ["rekognition:DetectModerationLabels"],
resources: ["*"],
});
imageModerationFunction.addToRolePolicy(rekognitionPolicy);
And we’re done. Time to head to main.ts and create our stack:
new ServerlessPdfContentModerationPipelineStack(app, 'ServerlessPdfContentModerationPipelineStack', {
targetDpi: 300,
minimum_moderation_confidence: 60,
});
I decided to use a moderation confidence threshold of 60. The right value depends on the type of content your application will see and what sort of requirements you need to satisfy. Finding a good value is about balancing the ratio of false positives and false negatives you’re willing to tolerate, and that usually needs a little bit of experimentation.
Testing the Stack
After deployment, navigate to S3 and locate your landing bucket (it will have a long generated name like serverlesspdfcontentmoderati-landingbucket72c76a11-use2yo9mxnka). Upload a PDF file—choose something reasonably sized as your Lambda may lack resources for very large files.
I created four test files for testing the solution:
- normal_doc: Normal document, has nothing out of the ordinary and serves as a baseline for testing.
- hate_doc: Same as our normal doc, but with a hate symbol inserted on page 3.
- lewd_doc: Same as our normal doc, but with a topless portrait of a woman on page 3.
- tobacco_doc: Same as our normal doc, but with an image of a person smoking on page 2.
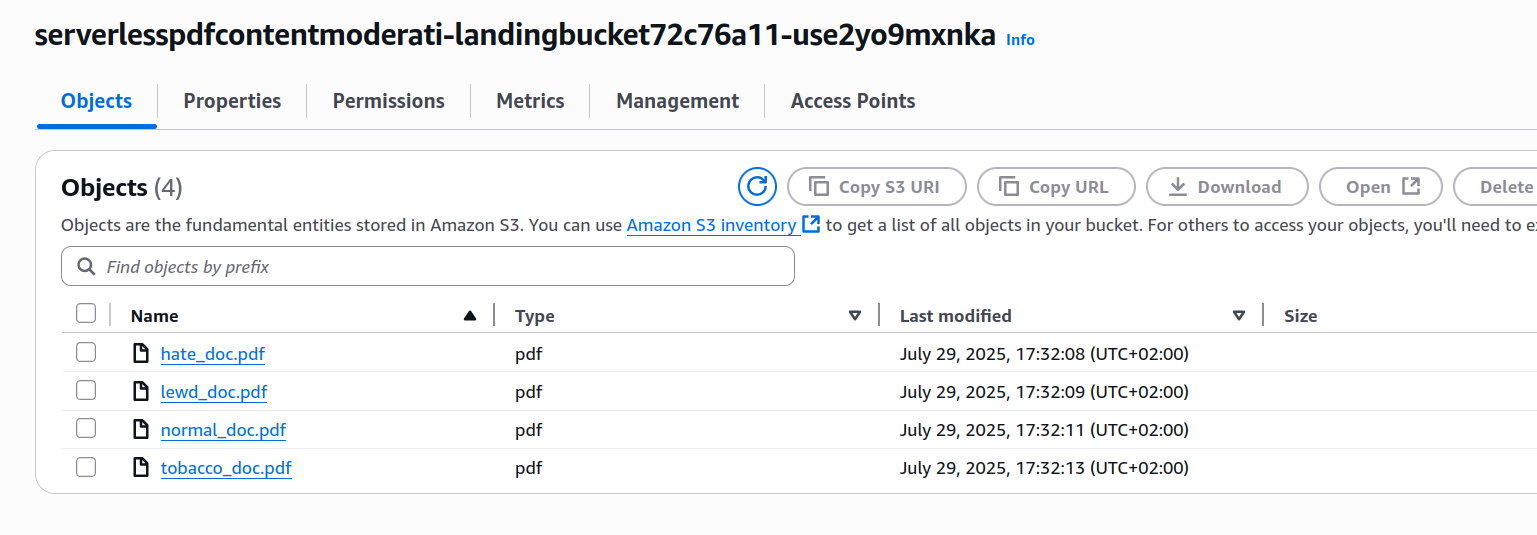
I uploaded all 4 files to the landing bucket and waited a few seconds, then headed to the DynamoDB panel and inspected the contents of my table.
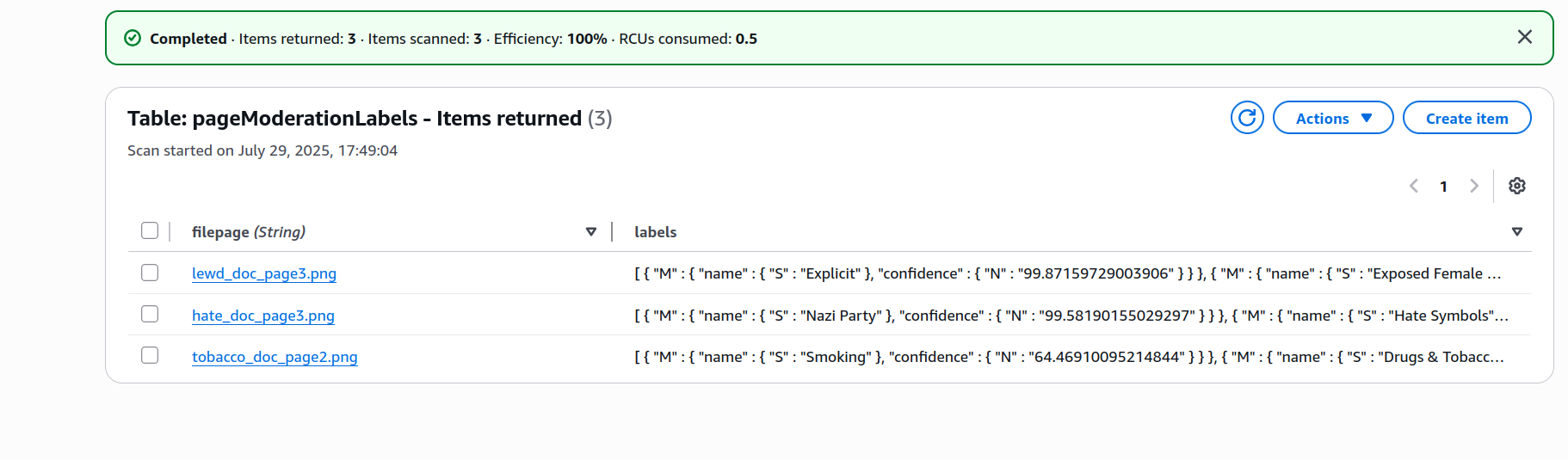
If you inspect the labels assigned to, say, the tobacco_doc, you’ll find data with this structure:
[
{
"M": {
"name": { "S": "Smoking" },
"confidence": { "N": "64.46910095214844" }
}
},
{
"M": {
"name": { "S": "Drugs & Tobacco Paraphernalia & Use" },
"confidence": { "N": "64.46910095214844" }
}
},
{
"M": {
"name": { "S": "Drugs & Tobacco" },
"confidence": { "N": "64.46910095214844" }
}
}
]
It’s working quite well—it assigned labels to all documents with content you’d typically want to moderate on some platforms, while leaving normal_doc out. You can also notice that the classifier feels more confident about the labels for the other documents than it does about the ones it assigned to tobacco_doc.
IMPORTANT! Always remember to delete your stack, either by running cdk destroy or by deleting it manually on the console.
Improvements and Experiments
- Would it be possible to combine our moderation pipeline and the text-extraction functionality we built before? How would you design and implement this joint solution?
- Why is it important to leave details such as
targetDpior the confidence threshold as configurable values outside of our stack? What advantages do you gain from this? - Now that we have the first part of the pipeline in place, what type of analysis or further processing is possible, and how would you accomplish that? DynamoDB can also emit events in response to changes within its tables—how can you capitalize on that to extend the workflow?
- Is it possible to send the bucket events to an SQS queue instead of sending them directly to each lambda function? What are the advantages and disadvantages of this approach?
- We have been using the same section at the beginning of the pipeline for two projects. It may be a good idea to create a custom construct including the first two buckets, the format transformation lambda, and all required permissions and event configurations. Give it a try, and think about what this construct’s interface should expose to the outside world.
With that, we managed to complete our second cloud experiment! The more you experiment and build, the better you understand the cloud ecosystem and how to build solutions using a variety of tools and services, so don’t be afraid to come up with your own experiments and modifications.
I hope you find this useful!