El código fuente para este artículo se puede encontrar aquí.
¡Bienvenido a otro experimento en la nube! La idea detrás de estos tutoriales prácticos es proporcionar experiencia práctica construyendo soluciones cloud-native de diferentes tamaños usando servicios de AWS y CDK. Nos enfocaremos en desarrollar experiencia en Infrastructure as Code, servicios de AWS y arquitectura en la nube mientras entendemos tanto el “cómo” como el “por qué” detrás de nuestras decisiones.
Combinando Soluciones
Este experimento en la nube es un poco diferente de los anteriores.
Hasta ahora, hemos empezado cada laboratorio con un problema que queremos resolver, y luego procedimos a diseñar y construir una solución desde cero usando mejores prácticas arquitecturales y un procedimiento paso a paso.
Este laboratorio se centra en resolver problemas combinando soluciones que hemos construido antes y reconfigurándolas de maneras inteligentes. Probablemente no necesitas construir soluciones desde cero para cada problema que tienes, así que aprender cómo usar piezas de sistemas que ya has hecho pegándolos es otra habilidad valiosa que dominar. Aún mejor, resolveremos nuestro problema agregando una herramienta particularmente útil a tu colección—una que probablemente será útil en tu carrera como arquitecto de la nube.
Empecemos.
Bloques de Construcción para una Nueva Solución
En las últimas semanas, creamos dos soluciones para procesar archivos PDF para diferentes fines:
- Un Pipeline de Transformación PDF Serverless, que extrae texto de archivos PDF
- Un Pipeline de Moderación PDF Serverless, que detecta imágenes potencialmente dañinas en archivos PDF
Recomiendo que les des una leída antes de proceder—es una buena idea familiarizarte con cómo resolvemos esos dos problemas por separado. Sus diagramas arquitecturales son (respectivamente):
Transformación:
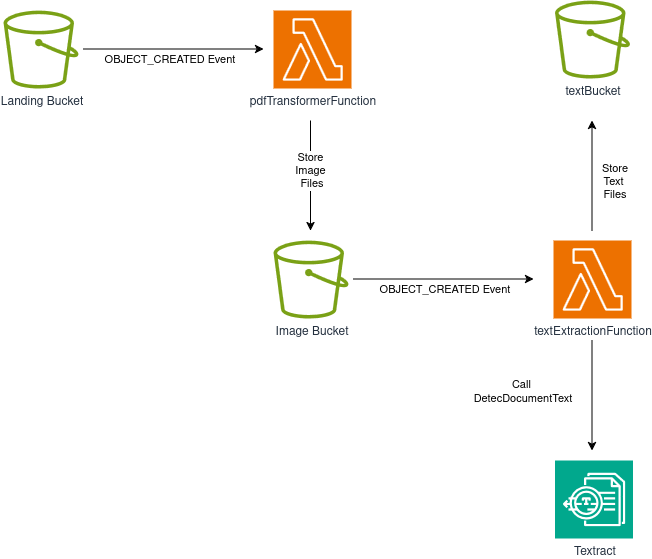
Moderación:
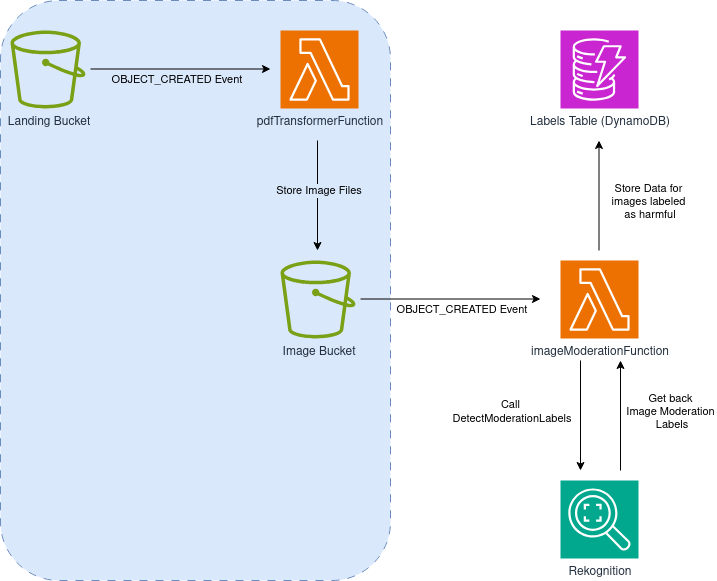
Nos gustaría combinar ambos pipelines para realizar moderación de contenido más sofisticada. Queremos poder detectar tanto contenido dañino que se muestra gráficamente, como al mismo tiempo encontrar contenido escrito del que podríamos querer deshacernos—como enlaces a sitios maliciosos o redacción no adecuada para los usuarios del sistema.
Queremos un sistema que esencialmente se vea así:
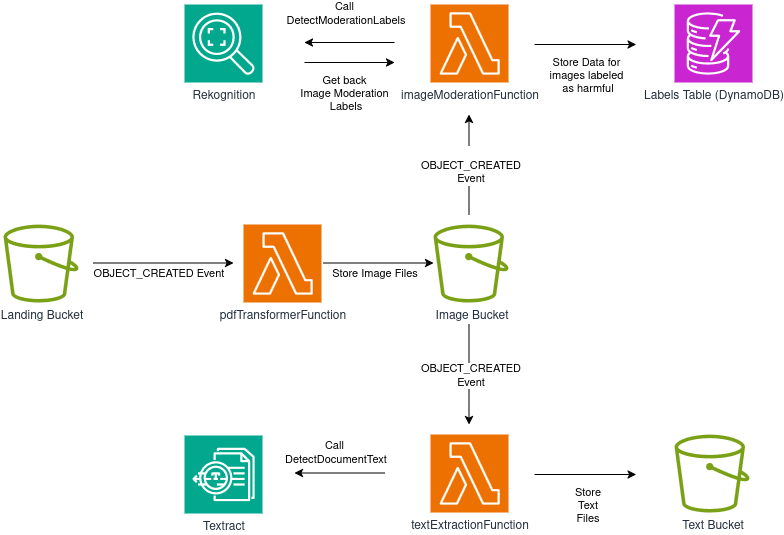
El Problema Principal
Nuestro problema principal es que el diagrama arquitectural que compartí arriba es imposible de implementar, al menos sin hacer un pequeño cambio.
No puedes “enganchar” el mismo evento S3 a diferentes funciones.
El evento OBJECT_CREATED se necesita tanto para imageModerationFunction como para textExtractionFunction, pero no es posible registrar el mismo evento a más de un objetivo al mismo tiempo.
Tenemos que encontrar una solución para este problema.
La Solución
La solución es súper simple: usar un Topic SNS para lograr event fan-out.
En el contexto de arquitecturas orientadas a eventos de computación en la nube, fan-out es un patrón donde un solo evento dispara múltiples procesos independientes aguas abajo. Hay diferentes maneras de lograr esto (podrías idear una solución muy elaborada que use EventBridge, filtros y un montón de colas SQS), pero por mucho la solución más simple es usar un Topic SNS con múltiples suscriptores lambda.
Ya hemos usado un Topic SNS para enviar un email a un suscriptor usuario. Además de suscriptores de email, ¡SNS también soporta otros tipos de suscripciones, incluso suscriptores de funciones lambda!
Con esto en mente, podemos re-diseñar nuestra solución así:
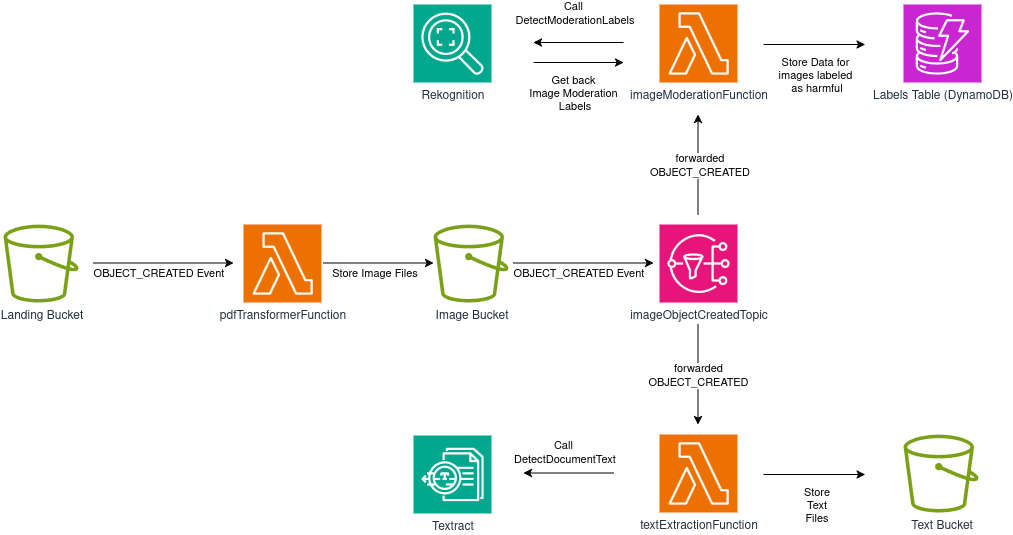
imageObjectCreatedTopic duplicará y reenviará eventos OBJECT_CREATED a ambos suscriptores (imageModerationFunction y textExtractionFunction), así ambas “ramas” del sistema tendrán los datos que requieren para funcionar apropiadamente.
Fan-out: ¿De Dónde Viene?
El término es un legado de la electrónica digital.
Fan-in se refiere al número de entradas que una puerta lógica puede manejar, fan-out es el número de entradas de puertas que son manejadas por la salida de una sola puerta. En otras palabras, fan-in es cuántas entradas una puerta puede manejar, y fan-out es cuántas entradas de otras puertas están actualmente conectadas a su salida.
Esto es más fácil de entender con un ejemplo.
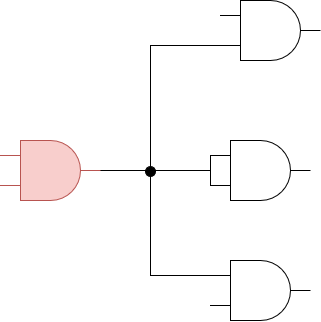
En el diagrama anterior, la puerta AND roja tiene un valor fan-in de 2, y un valor fan-out de 4 (hay 4 entradas a otras puertas siendo manejadas por la salida de nuestra puerta AND roja).
Es importante conocer el máximo fan-out que una puerta puede tolerar cuando se diseña un circuito digital—exceder este valor puede causar que la señal se degrade y afecte el comportamiento general de tu circuito.
En un mundo ideal podrías adjuntar tantas entradas como quieras a la salida de una puerta lógica sin degradación, pero en el mundo real hay impedancias de entrada y salida asociadas con cualquier familia lógica que ponen límites prácticos en las maneras que puedes conectar puertas lógicas. Todos los dispositivos tienen pequeñas resistencias y capacitancias que contribuyen a estos valores de impedancia.
Muy bien, eso fue suficiente para un pequeño desvío histórico—de vuelta a la computación en la nube.
Implementando los Cambios
Para este, solo mezclamos los stacks que creamos para los dos proyectos anteriores. Veamos el código para la solución completa y luego discutamos solo los aspectos nuevos.
import * as cdk from "aws-cdk-lib";
import { Construct } from "constructs";
import { aws_s3 as s3 } from "aws-cdk-lib";
import { aws_lambda as lambda } from "aws-cdk-lib";
import { aws_dynamodb as dynamo } from "aws-cdk-lib";
import { aws_s3_notifications as s3n } from "aws-cdk-lib";
import { aws_iam as iam } from "aws-cdk-lib";
import { aws_sns as sns } from "aws-cdk-lib";
import { aws_sns_subscriptions as subscriptions } from "aws-cdk-lib";
interface ServerlessPdfFullPipelineStackProps extends cdk.StackProps {
targetDpi: number;
minimum_moderation_confidence: number;
}
export class ServerlessPdfFullPipelineStack extends cdk.Stack {
constructor(
scope: Construct,
id: string,
props: ServerlessPdfFullPipelineStackProps
) {
super(scope, id, props);
const landingBucket = new s3.Bucket(this, "landingBucket", {
removalPolicy: cdk.RemovalPolicy.DESTROY,
autoDeleteObjects: true,
});
const imageBucket = new s3.Bucket(this, "imageBucket", {
removalPolicy: cdk.RemovalPolicy.DESTROY,
autoDeleteObjects: true,
});
const textBucket = new s3.Bucket(this, "textBucket", {
removalPolicy: cdk.RemovalPolicy.DESTROY,
autoDeleteObjects: true,
});
const labelsTable = new dynamo.Table(this, "moderationLabelsTable", {
partitionKey: {
name: "filepage",
type: dynamo.AttributeType.STRING,
},
tableName: `${this.stackName}-pageModerationLabels`,
removalPolicy: cdk.RemovalPolicy.DESTROY,
});
const pdfTransformerFunction = new lambda.DockerImageFunction(
this,
"pdfTransformFunction",
{
code: lambda.DockerImageCode.fromImageAsset("lambdas/pdf_to_image"),
environment: {
TARGET_DPI: String(props.targetDpi),
IMAGE_BUCKET_NAME: imageBucket.bucketName,
},
description: "Transforms a PDF into images, one per page",
memorySize: 512,
timeout: cdk.Duration.seconds(120),
}
);
const textExtractionFunction = new lambda.Function(
this,
"textExtractionFunction",
{
runtime: lambda.Runtime.RUBY_3_3,
code: lambda.Code.fromAsset("lambdas/text_extractor"),
handler: "text_extractor.handler",
environment: {
TEXT_BUCKET_NAME: textBucket.bucketName,
},
description: "Extracts text from each image that gets created",
timeout: cdk.Duration.seconds(120),
}
);
const imageModerationFunction = new lambda.Function(
this,
"imageModerationFunction",
{
runtime: lambda.Runtime.RUBY_3_3,
code: lambda.Code.fromAsset("lambdas/image_moderation"),
handler: "image_moderation.handler",
environment: {
MIN_CONFIDENCE: String(props.minimum_moderation_confidence),
DYNAMO_TABLE_NAME: labelsTable.tableName,
},
description:
"Uses Rekognition to detect harmful content, and stores results on a DynamoDB table",
timeout: cdk.Duration.seconds(30),
}
);
// Create an SNS topic and use event fanout
const snsTopic = new sns.Topic(this, "imageBucketObjectCreatedTopic", {
topicName: `${this.stackName}-imageBucketObjectCreatedTopic`,
displayName:
"SNS Topic for doing fan-out on the object_created events from the image S3 bucket",
});
// Enable buckets to emit events when objects are created
landingBucket.addEventNotification(
s3.EventType.OBJECT_CREATED,
new s3n.LambdaDestination(pdfTransformerFunction),
{ suffix: ".pdf" }
);
imageBucket.addEventNotification(
s3.EventType.OBJECT_CREATED,
new s3n.SnsDestination(snsTopic),
{ suffix: ".png" }
);
snsTopic.addSubscription(
new subscriptions.LambdaSubscription(textExtractionFunction)
);
snsTopic.addSubscription(
new subscriptions.LambdaSubscription(imageModerationFunction)
);
// Allow the lambda to read from the source bucket, and write on the target buckets and dynamo table
landingBucket.grantRead(pdfTransformerFunction);
imageBucket.grantWrite(pdfTransformerFunction);
imageBucket.grantRead(textExtractionFunction);
textBucket.grantWrite(textExtractionFunction);
imageBucket.grantRead(imageModerationFunction);
labelsTable.grantWriteData(imageModerationFunction);
// Allow the text extraction lambda function to query the TEXTRACT API
const textractPolicy = new iam.PolicyStatement({
actions: ["textract:DetectDocumentText"],
resources: ["*"],
});
textExtractionFunction.addToRolePolicy(textractPolicy);
// Same for the other lambda, but with Rekognition
const rekognitionPolicy = new iam.PolicyStatement({
actions: ["rekognition:DetectModerationLabels"],
resources: ["*"],
});
imageModerationFunction.addToRolePolicy(rekognitionPolicy);
}
}
Las nuevas secciones se ocupan de la creación de un Topic SNS. Nota que usamos el nombre del stack cuando asignamos un nombre de topic. Porque la mayoría de nombres de recursos no pueden repetirse, este es un detalle importante a tener en cuenta si quieres instanciar el stack múltiples veces:
const snsTopic = new sns.Topic(this, "imageBucketObjectCreatedTopic", {
topicName: `${this.stackName}-imageBucketObjectCreatedTopic`,
displayName:
"SNS Topic for doing fan-out on the object_created events from the image S3 bucket",
});
Y establecerlo como destino para eventos OBJECT_CREATED emitidos por el imageBucket:
imageBucket.addEventNotification(
s3.EventType.OBJECT_CREATED,
new s3n.SnsDestination(snsTopic),
{ suffix: ".png" }
);
Nota que esta vez no estamos usando un LambdaDestination, en su lugar usamos un SnsDestination apuntando a nuestro topic recién creado.
Luego solo agregamos las dos lambdas como suscriptores, así:
snsTopic.addSubscription(
new subscriptions.LambdaSubscription(textExtractionFunction)
);
snsTopic.addSubscription(
new subscriptions.LambdaSubscription(imageModerationFunction)
);
No hay necesidad de agregar manualmente permisos adicionales—todo funcionará fuera de la caja en esta configuración. Al estilo típico de CDK, implementar nuestro cambio fue muy fácil, ¡hemos terminado!
Ten Cuidado con los Cambios en la Estructura del Evento
Cuando implementas patrones fan-out con topics SNS, la carga útil del evento original se envuelve dentro de la estructura del mensaje SNS y se serializa como una cadena JSON. Esto significa que tus funciones Lambda necesitan actualizarse para extraer apropiadamente los datos del evento original de esta estructura anidada.
Por ejemplo, las primeras líneas de una de nuestras lambdas originalmente se veían así:
def handler(event:, context:)
bucket = event['Records'][0]['s3']['bucket']['name']
key = CGI.unescape(event['Records'][0]['s3']['object']['key'])
...
Con la nueva configuración, necesitamos cambiarlas a:
def handler(event:, context:)
s3_event = JSON.parse(event['Records'][0]['Sns']['Message'])
bucket = s3_event['Records'][0]['s3']['bucket']['name']
key = CGI.unescape(s3_event['Records'][0]['s3']['object']['key'])
text_bucket_name = ENV['TEXT_BUCKET_NAME']
...
Ahora tenemos acceso a los datos del evento original y podemos proceder sin problemas.
Probando la Solución
No hay necesidad de agregar nada nuevo aquí—el procedimiento de pruebas es el mismo que usamos para los dos pipelines anteriores: Solo sube un archivo PDF con contenido potencialmente dañino, y ve los resultados colocados tanto en el bucket de texto como en la tabla DynamoDB.
¡IMPORTANTE! Siempre recuerda eliminar tu stack ejecutando cdk destroy o eliminándolo manualmente en la consola.
Mejoras y Experimentos
- ¿Es posible enviar los eventos del bucket a una cola SQS en lugar de pasarlos directamente a cada función lambda? ¿Cuáles son las ventajas y desventajas de este enfoque?
- Asume que te gustaría agregar más “ramas” al Topic SNS, cada una con sus propias extensiones de pipeline. ¿Sería posible simplificar este procedimiento creando tu propio construct CDK personalizado? ¿Qué cosas son comunes a cada “rama,” y cómo te ayudaría este conocimiento a crear dicho construct?
- Ahora que tienes un bucket lleno de archivos de texto y una tabla DynamoDB con etiquetas de moderación—¡es hora de implementar la sección final del pipeline! Expande tu solución para que cuando se detecte un tipo particular de contenido (tu elección, realmente), el sistema elimine el archivo PDF original, y un administrador (tú) sea notificado por email de la eliminación. Las piezas de construcción para esta expansión pueden inferirse de la solución actual y un laboratorio anterior en el que implementamos alarmas de inventario.
¡Eso es todo! En este laboratorio usamos una forma rudimentaria de reutilización—reutilizamos una idea anterior e hicimos algunos ajustes para crear un sistema más grande y más útil que las partes individuales que lo componen. Reutilizamos nuestras ideas (¡genial!) y también algo de código que escribimos antes (bien).
Hay mejores maneras de reutilizar tu código. Otro enfoque habría sido crear cada stack individualmente y exponer los constructs relevantes al mundo exterior, ayudándonos a re-conectarlos desde afuera. Un enfoque aún mejor es identificar patrones comunes en nuestro diseño y ya sea usar constructs pre-construidos que implementen el patrón, o escribirlos nosotros mismos.
¡Espero que esto te sea útil!