The source code for this article can be found here.
Welcome to another cloud experiment! The idea behind these hands-on tutorials is to provide practical experience building cloud-native solutions of different sizes using AWS services and CDK. We’ll focus on developing expertise in Infrastructure as Code, AWS services, and cloud architecture while understanding both the “how” and “why” behind our choices.
Combining Solutions
This cloud experiment is a bit different from the previous ones.
Until now, we have started every lab with a problem we want to solve, and then proceeded to design and build a solution from scratch using architectural best practices and a step-by-step procedure.
This lab is centered around solving problems by combining solutions we have built before and reconfiguring them in clever ways. You probably don’t need to build solutions from scratch for every problem you have, so learning how to use pieces of systems you have already made by gluing them together is another valuable skill to master. Even better, we will solve our problem by adding a particularly useful tool to your collection—one that will likely come in handy in your career as a cloud architect.
Let’s get started.
Building Blocks for a New Solution
In the past few weeks, we created two solutions for processing PDF files for different ends:
- A Serverless PDF Transformation Pipeline, which extracts text from PDF files
- A Serverless PDF Moderation Pipeline, which detects potentially harmful images in PDF files
I recommend you give those a read before proceeding—it’s a good idea to become familiar with how we solve those two problems separately. Their architectural diagrams are (respectively):
Transformation:
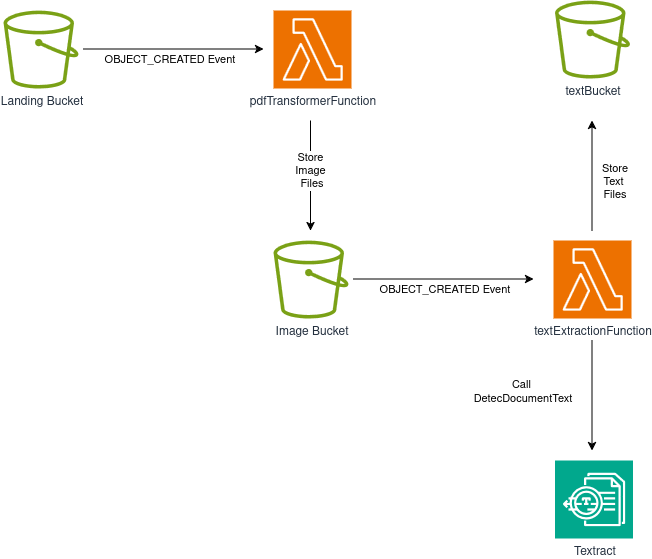
Moderation:
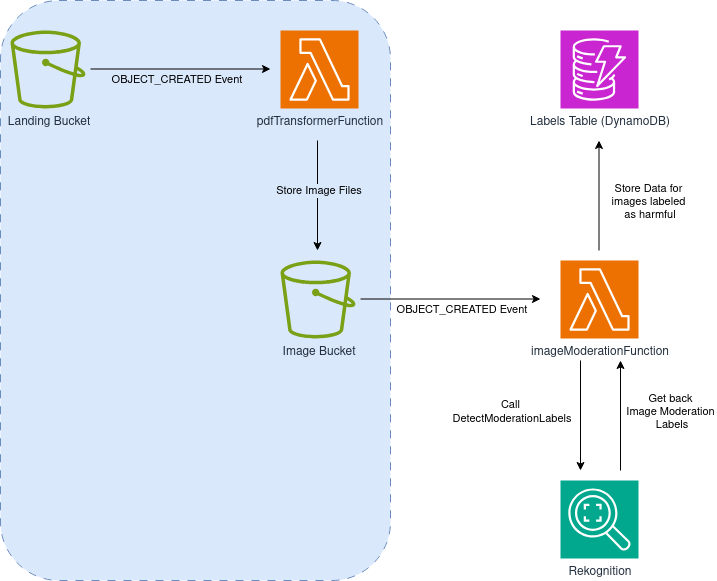
We would like to combine both pipelines to perform more sophisticated content moderation. We want to be able to detect both harmful content that is depicted graphically, and at the same time find written content we may want to get rid of—like links to malicious sites or wording not suitable for the users of the system.
We want a system that essentially looks like this:
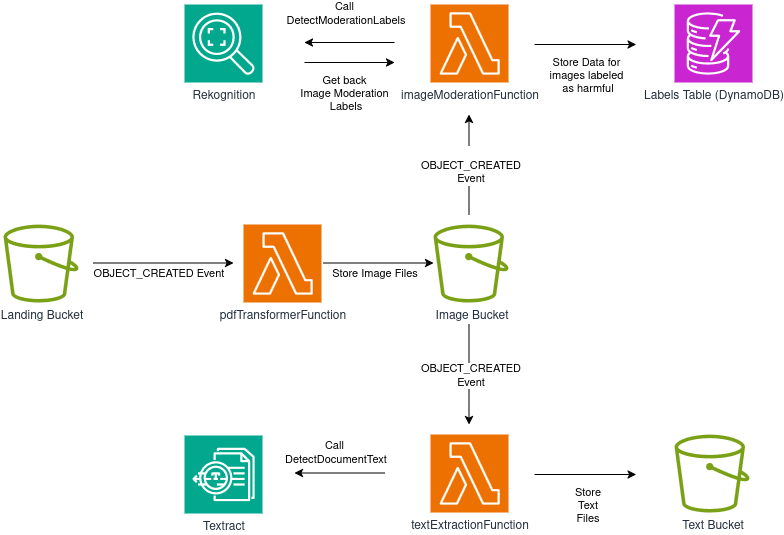
The Main Issue
Our main problem is that the architectural diagram I shared above is impossible to implement, at least without making one small change.
You cannot “hook” the same S3 event to different functions.
The OBJECT_CREATED event is needed for both the imageModerationFunction and textExtractionFunction, but it’s not possible to register the same event to more than one target at the same time.
We have to find a solution for this problem.
The Solution
The solution is super simple: use an SNS Topic to achieve event fan-out.
In the context of cloud computing event-driven architectures, fan-out is a pattern where a single event triggers multiple independent processes downstream. There are different ways of achieving this (you could come up with a very elaborate solution that uses EventBridge, filters and a bunch of SQS queues), but by far the simplest solution is using an SNS Topic with multiple lambda subscribers.
We have already used an SNS Topic for sending an email to a user subscriber. On top of email subscribers, SNS also supports other types of subscriptions, even lambda function subscribers!
With this in mind, we can re-design our solution like this:
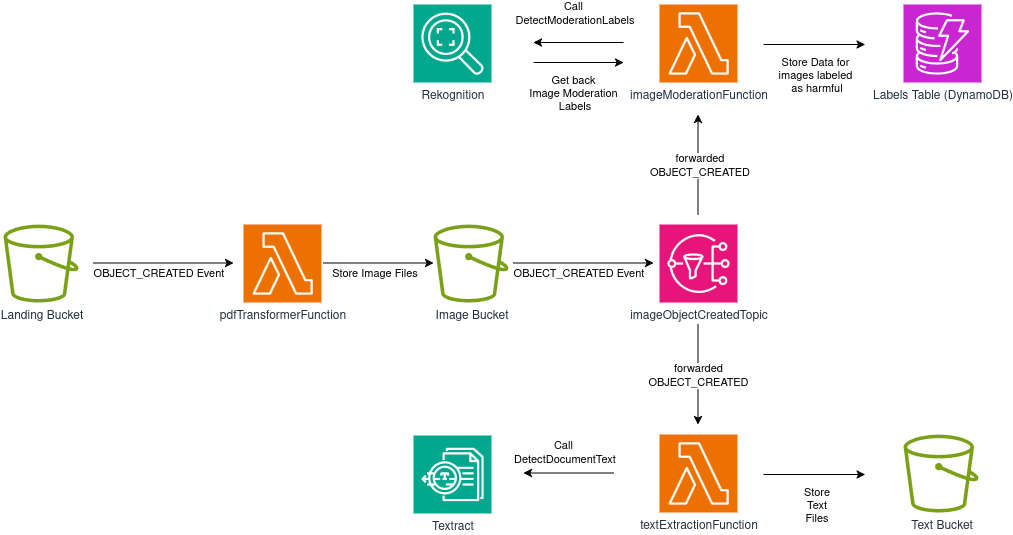
imageObjectCreatedTopic will duplicate and forward OBJECT_CREATED events to both subscribers (imageModerationFunction and textExtractionFunction), so both “branches” of the system will have the data they require to function properly.
Fan-out: Where Does it Come From?
The term is a legacy from digital electronics.
Fan-in refers to the number of inputs a logical gate can handle, fan-out is the number of gate inputs that are driven by a single gate’s output. In other words, fan-in is how many inputs a gate can handle, and fan-out is how many inputs from other gates are currently connected to its output.
This is easier to understand with an example.
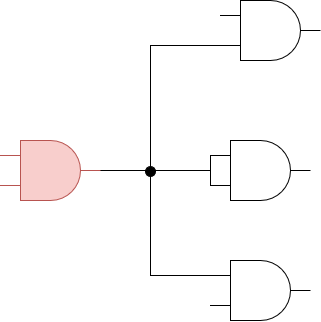
In the previous diagram, the red AND gate has a fan-in value of 2, and a fan-out value of 4 (there are 4 inputs to other gates being driven by the output of our red AND gate).
It’s important to know the maximum fan-out a gate can tolerate when designing a digital circuit—exceeding this value can cause the signal to degrade and affect the overall behavior of your circuit.
In an ideal world you would be able to attach as many inputs to the output of a logic gate without degradation, but in the real world there are input and output impedances associated with any logic family that put practical limits on the ways you can connect logic gates. All devices have small resistances and capacitances that contribute to these impedance values.
Very well, that was enough for a little historic detour—back to cloud computing.
Implementing the Changes
For this one, we just mash together the stacks we created for the two previous projects. Let’s see the code for the full solution and then discuss only the new aspects.
import * as cdk from "aws-cdk-lib";
import { Construct } from "constructs";
import { aws_s3 as s3 } from "aws-cdk-lib";
import { aws_lambda as lambda } from "aws-cdk-lib";
import { aws_dynamodb as dynamo } from "aws-cdk-lib";
import { aws_s3_notifications as s3n } from "aws-cdk-lib";
import { aws_iam as iam } from "aws-cdk-lib";
import { aws_sns as sns } from "aws-cdk-lib";
import { aws_sns_subscriptions as subscriptions } from "aws-cdk-lib";
interface ServerlessPdfFullPipelineStackProps extends cdk.StackProps {
targetDpi: number;
minimum_moderation_confidence: number;
}
export class ServerlessPdfFullPipelineStack extends cdk.Stack {
constructor(
scope: Construct,
id: string,
props: ServerlessPdfFullPipelineStackProps
) {
super(scope, id, props);
const landingBucket = new s3.Bucket(this, "landingBucket", {
removalPolicy: cdk.RemovalPolicy.DESTROY,
autoDeleteObjects: true,
});
const imageBucket = new s3.Bucket(this, "imageBucket", {
removalPolicy: cdk.RemovalPolicy.DESTROY,
autoDeleteObjects: true,
});
const textBucket = new s3.Bucket(this, "textBucket", {
removalPolicy: cdk.RemovalPolicy.DESTROY,
autoDeleteObjects: true,
});
const labelsTable = new dynamo.Table(this, "moderationLabelsTable", {
partitionKey: {
name: "filepage",
type: dynamo.AttributeType.STRING,
},
tableName: `${this.stackName}-pageModerationLabels`,
removalPolicy: cdk.RemovalPolicy.DESTROY,
});
const pdfTransformerFunction = new lambda.DockerImageFunction(
this,
"pdfTransformFunction",
{
code: lambda.DockerImageCode.fromImageAsset("lambdas/pdf_to_image"),
environment: {
TARGET_DPI: String(props.targetDpi),
IMAGE_BUCKET_NAME: imageBucket.bucketName,
},
description: "Transforms a PDF into images, one per page",
memorySize: 512,
timeout: cdk.Duration.seconds(120),
}
);
const textExtractionFunction = new lambda.Function(
this,
"textExtractionFunction",
{
runtime: lambda.Runtime.RUBY_3_3,
code: lambda.Code.fromAsset("lambdas/text_extractor"),
handler: "text_extractor.handler",
environment: {
TEXT_BUCKET_NAME: textBucket.bucketName,
},
description: "Extracts text from each image that gets created",
timeout: cdk.Duration.seconds(120),
}
);
const imageModerationFunction = new lambda.Function(
this,
"imageModerationFunction",
{
runtime: lambda.Runtime.RUBY_3_3,
code: lambda.Code.fromAsset("lambdas/image_moderation"),
handler: "image_moderation.handler",
environment: {
MIN_CONFIDENCE: String(props.minimum_moderation_confidence),
DYNAMO_TABLE_NAME: labelsTable.tableName,
},
description:
"Uses Rekognition to detect harmful content, and stores results on a DynamoDB table",
timeout: cdk.Duration.seconds(30),
}
);
// Create an SNS topic and use event fanout
const snsTopic = new sns.Topic(this, "imageBucketObjectCreatedTopic", {
topicName: `${this.stackName}-imageBucketObjectCreatedTopic`,
displayName:
"SNS Topic for doing fan-out on the object_created events from the image S3 bucket",
});
// Enable buckets to emit events when objects are created
landingBucket.addEventNotification(
s3.EventType.OBJECT_CREATED,
new s3n.LambdaDestination(pdfTransformerFunction),
{ suffix: ".pdf" }
);
imageBucket.addEventNotification(
s3.EventType.OBJECT_CREATED,
new s3n.SnsDestination(snsTopic),
{ suffix: ".png" }
);
snsTopic.addSubscription(
new subscriptions.LambdaSubscription(textExtractionFunction)
);
snsTopic.addSubscription(
new subscriptions.LambdaSubscription(imageModerationFunction)
);
// Allow the lambda to read from the source bucket, and write on the target buckets and dynamo table
landingBucket.grantRead(pdfTransformerFunction);
imageBucket.grantWrite(pdfTransformerFunction);
imageBucket.grantRead(textExtractionFunction);
textBucket.grantWrite(textExtractionFunction);
imageBucket.grantRead(imageModerationFunction);
labelsTable.grantWriteData(imageModerationFunction);
// Allow the text extraction lambda function to query the TEXTRACT API
const textractPolicy = new iam.PolicyStatement({
actions: ["textract:DetectDocumentText"],
resources: ["*"],
});
textExtractionFunction.addToRolePolicy(textractPolicy);
// Same for the other lambda, but with Rekognition
const rekognitionPolicy = new iam.PolicyStatement({
actions: ["rekognition:DetectModerationLabels"],
resources: ["*"],
});
imageModerationFunction.addToRolePolicy(rekognitionPolicy);
}
}
The new sections deal with the creation of an SNS Topic. Note that we use the name of the stack when assigning a topic name. Because most resource names cannot be repeated, this is an important detail to keep in mind if you want to instantiate the stack multiple times:
const snsTopic = new sns.Topic(this, "imageBucketObjectCreatedTopic", {
topicName: `${this.stackName}-imageBucketObjectCreatedTopic`,
displayName:
"SNS Topic for doing fan-out on the object_created events from the image S3 bucket",
});
And setting it as a destination for OBJECT_CREATED events emitted by the imageBucket:
imageBucket.addEventNotification(
s3.EventType.OBJECT_CREATED,
new s3n.SnsDestination(snsTopic),
{ suffix: ".png" }
);
Note that this time we are not using a LambdaDestination, instead we use a SnsDestination targeting our newly-created topic.
Then we just add the two lambdas as subscribers, like this:
snsTopic.addSubscription(
new subscriptions.LambdaSubscription(textExtractionFunction)
);
snsTopic.addSubscription(
new subscriptions.LambdaSubscription(imageModerationFunction)
);
There is no need to manually add any additional permissions—everything will work out of the box in this setup. In typical CDK fashion, implementing our change was very easy, we are done!
Watch Out For Changes in Event Structure
When implementing fan-out patterns with SNS topics, the original event payload gets wrapped within the SNS message structure and serialized as a JSON string. This means your Lambda functions need to be updated to properly extract the original event data from this nested structure.
For example, the first few lines of one of our lambdas originally looked like this:
def handler(event:, context:)
bucket = event['Records'][0]['s3']['bucket']['name']
key = CGI.unescape(event['Records'][0]['s3']['object']['key'])
...
With the new setup, we need to change them to:
def handler(event:, context:)
s3_event = JSON.parse(event['Records'][0]['Sns']['Message'])
bucket = s3_event['Records'][0]['s3']['bucket']['name']
key = CGI.unescape(s3_event['Records'][0]['s3']['object']['key'])
text_bucket_name = ENV['TEXT_BUCKET_NAME']
...
Now we have access to the original event’s data and we can proceed without trouble.
Testing the Solution
No need to add anything new here—the testing procedure is the same we used for the two previous pipelines: Just upload a PDF file with potentially harmful content, and see the results placed in both the text bucket and the DynamoDB table.
IMPORTANT! Always remember to delete your stack by running cdk destroy or deleting it manually in the console.
Improvements and Experiments
- Is it possible to send the bucket events to an SQS queue instead of passing them directly to each lambda function? What are the advantages and disadvantages of this approach?
- Assume you would like to add more “branches” to the SNS Topic, each with their own pipeline extensions. Would it be possible to simplify this procedure by creating your own custom CDK construct? What things are common to each “branch,” and how would this knowledge help you create said construct?
- Now that you have a bucket full of text files and a DynamoDB table with moderation labels—it’s time to implement the pipeline’s final section! Expand your solution so that whenever a particular type of content is detected (your choice, really), the system deletes the original PDF file, and an administrator (you) gets notified by email of the deletion. The building pieces for this expansion can be inferred from the current solution and a previous lab in which we implemented inventory alarms.
That’s it! In this lab we used a rudimentary form of reuse—we repurposed a previous idea and made some adjustments to create a system bigger and more useful than the individual parts that compose it. We reused our ideas (great!) and also some code we wrote before (alright).
There are better ways of reusing your code. Another approach would have been to create each stack individually and expose the relevant constructs to the outside world, helping us re-wire them from the outside. An even better approach is to identify common patterns in our design and either use pre-built constructs that implement the pattern, or write them ourselves.
I hope you find this useful!